
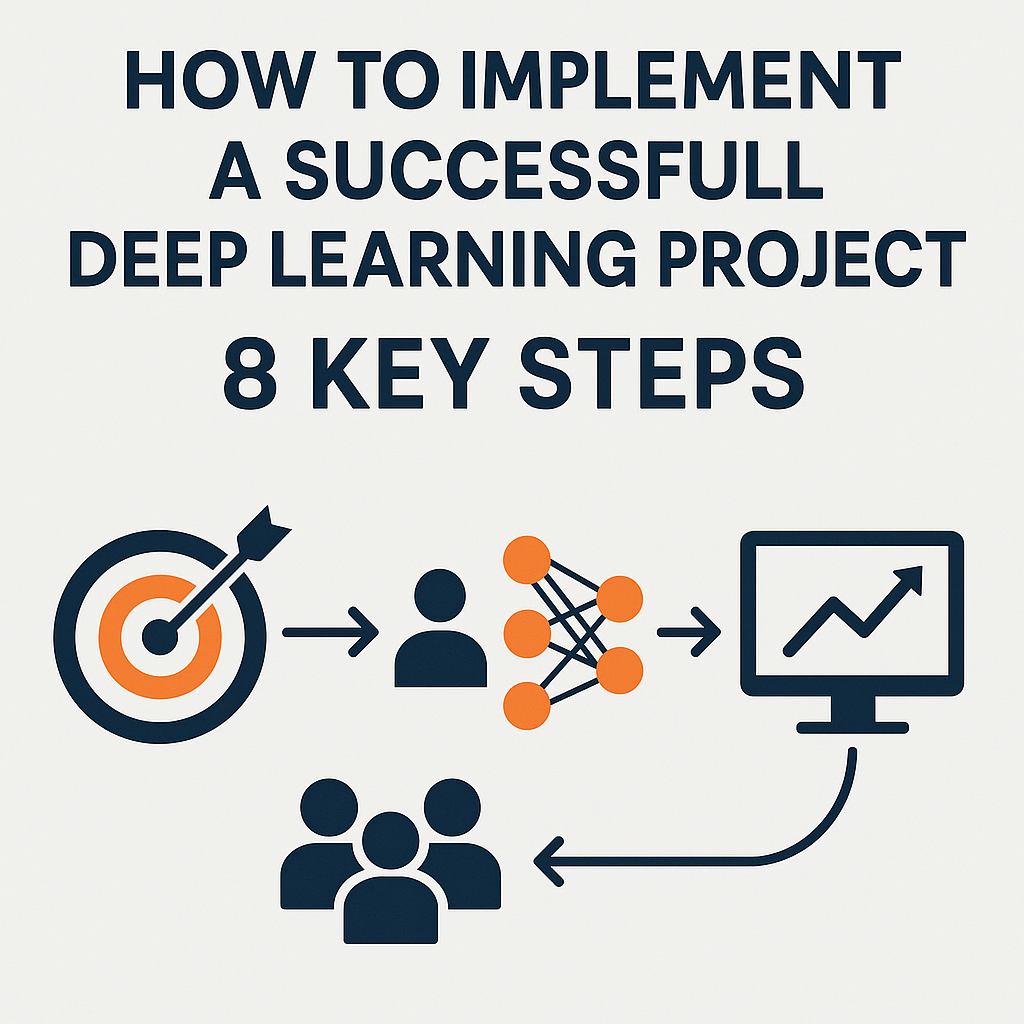
In several fields, like banking and health care, deep learning has made a big difference. It also helps with things like identifying photos, interpreting natural language, and making cars drive themselves. But a lot of businesses have problems moving from proof of concept to production. This expert tutorial will teach you eight crucial steps for designing, constructing, deploying, and keeping an eye on a deep learning project that can genuinely help your organization.
Deep learning systems are not like conventional software since they learn from data and need particular techniques to work. There are a lot of difficulties that happen a lot, such as:
- Quality and labeling of data
- The model is either doing too well or not well enough.
- Costs of manufacturing things and making them bigger
- Being honest and following the rules
Step 1: Decide what success means to you and what your goals and criteria are. Be clear about what you want your firm to do
First, you need to figure out what’s wrong with the business and how deep learning can assist fix it. A retailer might ask, “Can we automate checking the quality of the pictures?” or “Can we guess when customers will leave?”
One of the most crucial things to do is communicate to stakeholders, have requirement workshops, and figure out the return on investment (ROI).
Deliverables: a description of the problem and key performance indicators (KPIs) such as accuracy, latency, and savings on costs.
1.2 Make a plan for success
- What are qualitative and quantitative metrics?
- The F1-score and ROC AUC are two ways to measure how accurate a categorization is.
- Two examples of performance measures are latency and throughput.
- Business KPIs, such as higher revenue and happier consumers,
Put these in a project charter so that everyone knows what they need to do.
Step 2: Put the proper people and products together
2.1 The Most Important Jobs
A normal deep learning team has:
- People that work with data undertake research and make prototypes.
- Machine Learning Engineers get models ready to use.
- Data engineers build pipelines and keep an eye on storage.
- Experts in DevOps and MLOps to set up CI/CD and monitoring.
- People who know a lot about a field think about the rules of ethics and the business scenario.
2.2 Tools and Infrastructure
You can select between on‑premises, cloud, or hybrid installations based on the size of your organization and how much money you have. Popular platforms:
- AWS SageMaker, Google AI Platform, and Azure ML are all cloud‑based services.
- There are frameworks like TensorFlow (link), PyTorch (link), and Keras (link).
- MLflow, Kubeflow, and TFX are all tools that help with MLOps.
You should think about how much storage space and GPUs/TPUs you require, as well as if you are following standards like HIPAA and GDPR.
Step 3: Collecting and Marking Data
3.1 Find and Collect Data
It needs data for deep learning to work. Consider:
- Logs, transactional databases, and CRM are all instances of internal sources.
- ImageNet, COCO, and APIs are all instances of sources that are not internal.
Get authorization to use the data and keep it safe.
3.2 Putting in data and giving it a name
When models are labeled appropriately, they work better. You can choose from the following:
- In‑house teams who add notes to sensitive areas like healthcare.
- Crowdsourcing sites include Amazon Mechanical Turk and Labelbox.
- Tools that automatically label objects to make common tasks go faster.
Use consensus labeling, spot checks, and inter‑annotator agreement to make sure the quality is high.
Step 4: Preprocessing and Exploratory Data Analysis (EDA)
4.1 Looking at the Data
Know what your data set looks like:
- The way qualities, missing values, and outliers are spread out.
- Finding multicollinearity with correlation analysis.
- Histograms, scatter plots, and PCA can all help you perceive things.
- In Jupyter notebooks, you may learn by doing.
4.2 Getting the Data Ready and Cleaning It
Before processing, humans frequently undertake several things:
- Using the mean or mode (mean/mode imputation) or k‑NN to fill in the gaps where values are absent.
- Two approaches to make data standard and typical are MinMaxScaler and StandardScaler.
- Adding more information to photographs (by randomly flipping or rotating them) or text (by replacing words with words that mean the same thing)
- Use embeddings for text and Fourier transformations for signals when you are feature engineering.
You can maintain track of the many versions of data transformations with tools like DVC (link) so you can do them again.
Step 5: Choose a model and make a strategy for the architecture.
5.1 Pick the Right Model
Pick one of these:
- Models that have already been trained for computer vision, such ResNet and EfficientNet, or for natural language processing, like BERT and GPT.
- Custom architectures, like U‑Net for segmentation, might meet specific needs in a field.
Think about the model’s size, how fast it can make predictions, and how accurate it is.
5.2 Changing Hyperparameters
Here are some things you can do to make hyperparameters better:
- Grid Search or Random Search (GridSearchCV from scikit‑learn).
- Bayesian Optimization (Optuna, Hyperopt)
- Tools that can work on their own, including Google Vizier and Ray Tune.
Use MLflow or similar experiment tracking system to keep track of your experiments and the outcomes.
Step 6: Teaching and Checking
6.1 Set up training pipelines
It should be automatic to load data, group it, and store model checkpoints. You can use the DataLoader function from PyTorch or the tf.data function from TensorFlow.
6.2 Don’t Overfit
These are the best things to do:
- Regularization, which is sometimes called weight decay in L1 and L2.
- Dropout and Batch Normalization.
- They stopped early because they lost their validation.
6.3 Sets of Holdouts and Cross-Validation
You can use k‑fold cross‑validation or a different test set to check how well your model works with new data.
Step 7: Using it and expanding it
7.1 Serving the Model
Choose a way to serve:
- REST‑based APIs that work with both TorchServe and TensorFlow Serving.
- You don’t require a server to use AWS Lambda or Google Cloud Functions for inference.
- Deployment on edge devices (TensorFlow Lite, ONNX Runtime).
Check that the endpoints can handle the required latency and throughput.
7.2 Writing down what you see
Set up regular checks for:
- There is data drift and concept drift, just like there is with Evidently AI.
- How quickly and accurately the model works.
- Using things like the CPU, GPU, and memory.
Set up notifications and automated rollbacks when performance drops.
Step 8: Maintenance, management, and progress that never stops
8.1 Getting new versions and going through training again
As new data comes in, set up recurring training sessions. Automate the process of building and delivering models with CI/CD pipelines.
8.2 Use frameworks for governance that follow the rules, keep people safe, and are ethical:
- Checks for fairness to cut down on bias.
- SHAP or LIME can help you figure out what your forecasts mean.
- Two strategies to protect your data are to make sure your data pipelines are secure and to make sure your data is adversarially robust.
8.3 Keeping records and exchanging information
Keep detailed records:
- Model cards (link) for being truthful.
- Data sheets for data sets (link).
- Runbooks for fixing problems.
These are common inquiries (FAQs)
Q1: How much data do I need for a deep learning project?
A: Deep learning works best with large datasets, such as tens of thousands of samples. If you utilize pretrained weights (link), you can still get good results with smaller datasets (a few thousand).
Q2: Should I start with TensorFlow or PyTorch?
A: A lot of people know about and utilize both. You can use TensorFlow on phones and tablets, and it offers tools for production (TF Serving, TFX). Researchers prefer PyTorch because its API is easy to use and its graphs vary over time. Choose based on what the team knows and what the environment needs.
Q3: What should I do if my lessons aren’t fair?
A: Some strategies to do this are SMOTE (over‑sampling the minority class), under‑sampling the majority, utilizing class weights during training, or generating fake data.
Q4: What is the difference between batch normalizing and layer normalization?
A: Batch normalization normalizes throughout the batch dimension, although it can be unstable when the batch size is small. Layer normalization normalizes across feature dimensions and is a common aspect of NLP models like Transformers.
Q5: How often should I retrain my model while it’s being used?
A: It depends on how fast the data changes. Check performance often, and if validation metrics fall below a particular level, like 2% to 5%, retrain.
To sum up, you need to design your deep learning project carefully, know how to perform it, and have the right infrastructure in place for it to succeed. If you organize your deep learning initiatives well, they will be both new and last a long time.
References
- TensorFlow Documentation. https://www.tensorflow.org
- PyTorch Documentation. https://pytorch.org
- Google Cloud AI Platform. https://cloud.google.com/ai-platform
- AWS SageMaker. https://aws.amazon.com/sagemaker
- B. Settles, “Active Learning Literature Survey,” University of Wisconsin–Madison, Technical Report 1648, 2009. https://burrsettles.com/pub/settles.activelearning.pdf
- Mitchell, M., “Model Cards for Model Reporting,” ACM Conference on Fairness, Accountability, and Transparency, 2019. https://modelcards.withgoogle.com
- Gebru, T. et al., “Datasheets for Datasets,” arXiv:1803.09010, 2018. https://arxiv.org/abs/1803.09010
- Lundberg, S. M. & Lee, S.-I., “A Unified Approach to Interpreting Model Predictions,” NIPS 2017. https://arxiv.org/abs/1705.07874
- He, K., Zhang, X., Ren, S., & Sun, J., “Deep Residual Learning for Image Recognition,” CVPR 2016. https://arxiv.org/abs/1512.03385
- Devlin, J. et al., “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” NAACL 2019. https://arxiv.org/abs/1810.04805

















1 Comment