
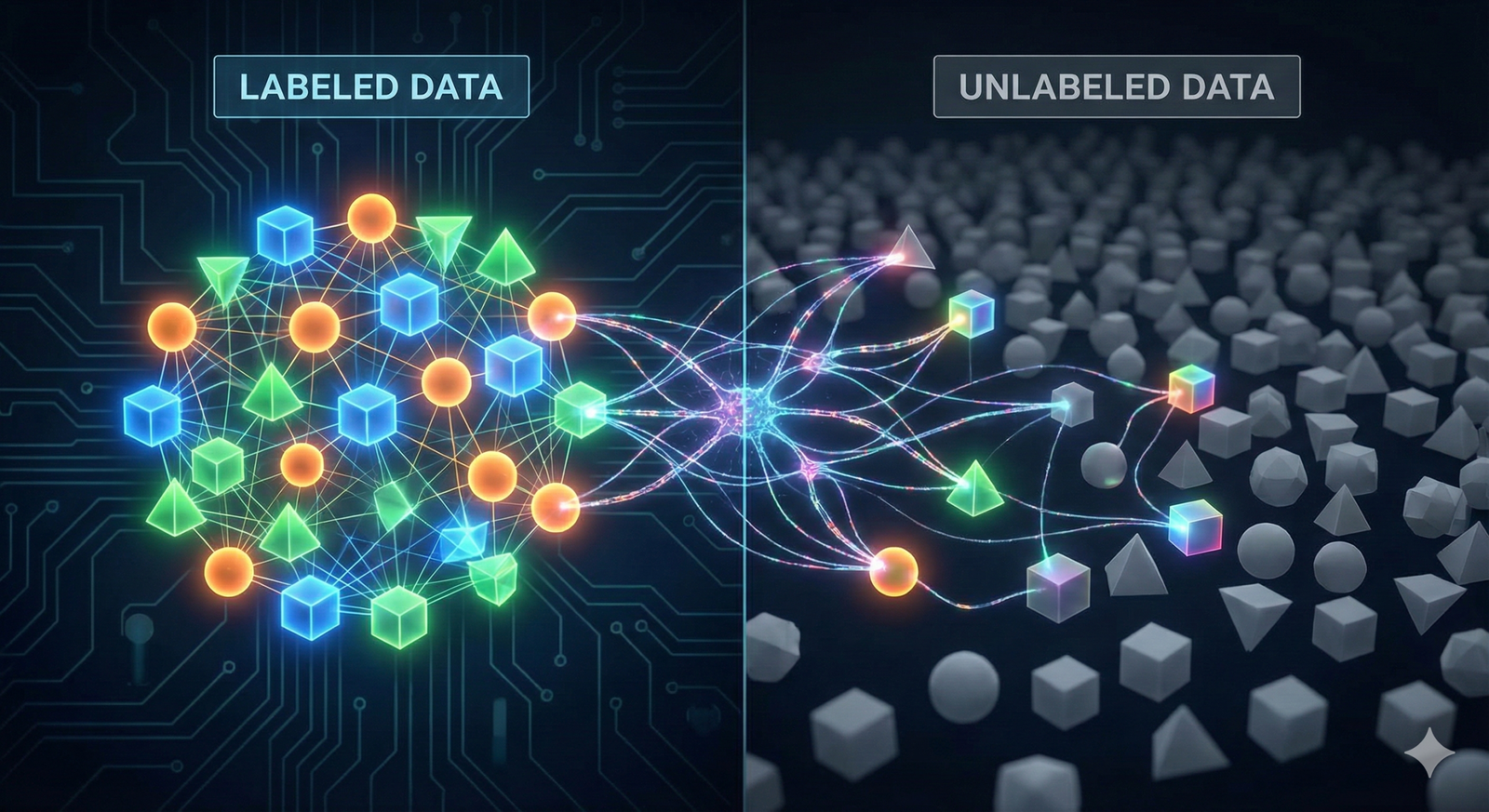
In the world of machine learning, data is fuel, but labels are the refined gasoline that actually powers the engine. For years, the dominant paradigm has been supervised learning, which relies on massive datasets where every single image, sentence, or audio clip is meticulously tagged by a human. But what happens when you have a mountain of raw data but only a handful of labels?
This is the reality for most industries. A hospital might have thousands of X-rays but only a few hundred diagnosed by a radiologist. A bank has millions of transaction logs but only a tiny fraction flagged as fraud. Labeling data is slow, expensive, and difficult to scale.
Enter semi-supervised learning (SSL). It is the pragmatic middle ground between supervised learning (which knows everything about a little data) and unsupervised learning (which knows nothing about a lot of data). By teaching algorithms to learn from a small set of labeled examples and a large volume of unlabeled ones, SSL unlocks the potential of data that would otherwise be discarded.
Key Takeaways
- The Best of Both Worlds: SSL combines the guidance of supervised learning with the exploration of unsupervised learning to improve model accuracy with fewer labels.
- Cost Efficiency: It significantly reduces the budget and time required for data annotation, making AI projects viable in resource-constrained environments.
- Core Assumptions: SSL relies on specific mathematical assumptions—continuity, clustering, and manifold structures—to propagate labels correctly.
- Modern Techniques: Advanced methods like consistency regularization and pseudo-labeling have revolutionized how models handle unlabeled data.
- Real-World Impact: From medical diagnosis to speech recognition, SSL is solving problems where expert human labeling is the bottleneck.
Who This Is For (And Who It Isn’t)
- This guide is for: Data scientists, machine learning engineers, and technical product managers who are dealing with “data rich, label poor” scenarios. It is also suitable for students and researchers looking for a comprehensive overview of modern SSL techniques.
- This guide is not for: Absolute beginners to programming who have never trained a basic model (e.g., linear regression). While we minimize complex math, a basic understanding of what a “model,” “training,” and “loss function” are will be helpful.
In Scope vs. Out of Scope
In this guide, semi-supervised learning refers to training a specific predictive task (like classification or regression) using both labeled and unlabeled data simultaneously.
- IN Scope: Self-training, consistency regularization, graph-based methods, and deep learning approaches to SSL.
- OUT of Scope: Pure unsupervised learning (clustering without any labels), pure transfer learning (unless used in conjunction with SSL), and few-shot learning (which focuses on generalization rather than leveraging unlabeled data).
1. The Data Problem: Why We Need Semi-Supervised Learning
To understand why semi-supervised learning is critical, we have to look at the economics of data. We are currently generating zettabytes of data, but the capacity to annotate that data has not kept pace.
The High Cost of Annotation
In standard supervised learning, the relationship is linear: if you want a better model, you generally need more labeled data. However, acquiring labels is often the most expensive part of the pipeline.
- Expertise Bottlenecks: In fields like pathology or geology, you cannot use crowdsourcing platforms. You need highly paid experts to label the data.
- Time Constraints: Labeling a single 3D LIDAR scan for autonomous driving can take hours.
- Privacy Concerns: In finance and healthcare, sharing data with third-party annotators is often legally impossible.
The Unlabeled Ocean
While labels are scarce, raw data is abundant. The internet is full of unlabeled images; sensors collect unlabeled readings 24/7. Semi-supervised learning rests on the premise that this “dark matter” of data contains valuable information about the structure of the domain, even if it lacks explicit tags.
2. Core Concepts: How SSL Works
Semi-supervised learning isn’t magic; it doesn’t create information out of thin air. Instead, it relies on specific structural assumptions about the data. If these assumptions hold, the model can infer the labels of the unlabeled points based on their relationship to the labeled ones.
The Three Pillars of SSL
For SSL to work, the data generally needs to satisfy at least one of these three assumptions:
1. The Continuity Assumption
This assumption states that points that are close to each other in the feature space are likely to share the same label. Ideally, the decision boundary (the line separating Class A from Class B) should pass through low-density regions where there is little data, rather than cutting through a dense cloud of points. This allows the model to push the boundary away from the data clusters.
2. The Cluster Assumption
This is an extension of continuity. It suggests that data points tend to form discrete clusters, and points within the same cluster likely belong to the same class. If a labeled point sits inside a cluster of unlabeled points, SSL algorithms infer that the whole cluster likely shares that label.
3. The Manifold Assumption
In high-dimensional data (like images or audio), the data points don’t fill the entire space randomly. Instead, they lie on a lower-dimensional structure called a “manifold.” Imagine a sheet of paper (2D) crumbled up into a ball (3D). The data points are on the paper. Even though they look complex in 3D, their intrinsic structure is 2D. SSL uses this manifold to interpolate labels between data points that might seem far apart in raw distance but are close on the manifold.
3. Major Approaches and Algorithms
Semi-supervised learning has evolved from simple heuristics to complex deep learning frameworks. Here are the primary methods used today.
Self-Training (Pseudo-Labeling)
This is one of the oldest and most intuitive methods. It involves a cyclical process:
- Train: Train a model on the small set of labeled data.
- Predict: Use that model to make predictions on the unlabeled data.
- Select: Take the predictions where the model is most confident (e.g., probability > 95%) and treat them as “pseudo-labels.”
- Retrain: Add these pseudo-labeled examples to the training set and retrain the model.
- Repeat: Continue the cycle until performance plateaus.
Why it matters: It is wrapper-agnostic, meaning you can apply it to almost any classifier (Random Forest, SVM, Neural Net). The Risk: If the model makes a confident mistake early on, it reinforces that mistake in future rounds, leading to “confirmation bias” or drifting.
Consistency Regularization
This is the dominant approach in modern deep learning (e.g., in computer vision). The core idea is: If I slightly change an image (flip it, add noise), the model’s prediction should remain the same.
In SSL, you don’t know the correct label for an unlabeled image, but you know that the model should be consistent.
- Mechanism: You take an unlabeled image and create two augmented versions of it. You feed both into the network. Even without a label, you can calculate a loss (penalty) if the network outputs different predictions for the two versions. This forces the model to learn robust features.
- Notable Algorithms:
- Pi-Model: Penalizes the difference in outputs between two different drop-out realizations of the network.
- Mean Teacher: Maintains an exponential moving average of the model weights to create a more stable target.
- FixMatch: A state-of-the-art method that combines consistency regularization with pseudo-labeling. It generates a pseudo-label from a weakly augmented image and enforces the model to predict that label on a strongly augmented version of the same image.
Graph-Based Methods
Graph methods view the dataset as a network. Each data point is a “node,” and the similarity between points forms the “edges.”
- Label Propagation: Imagine pouring colored dye (labels) onto the labeled nodes. The dye flows along the edges to the neighbors. Strongly connected nodes get more dye. Eventually, the dye settles, and unlabeled nodes adopt the color that reached them most strongly.
- Application: These are particularly effective for transductive learning, where you have a fixed dataset and just want to label the specific unlabeled points you currently possess.
Generative Models (VAEs and GANs)
Generative approaches try to model the distribution of the data itself.
- Variational Autoencoders (VAEs): Can be used to learn a latent representation of the data using both labeled and unlabeled sets. The classification happens on this compressed, more meaningful representation.
- Generative Adversarial Networks (GANs): In Semi-Supervised GANs, the discriminator is modified to predict K+1 classes (the K real classes plus one “fake” class). Unlabeled real data helps the discriminator learn what “real” images look like, which indirectly helps it separate the specific classes.
4. Implementation Guide: SSL in Practice
Implementing semi-supervised learning requires careful planning. It is not always a “plug and play” solution.
Prerequisites
Before diving into SSL, ensure:
- Baseline: You have a supervised baseline. Train a model on just your labeled data. If this performance is already acceptable, SSL might be over-engineering.
- Data Quality: Your unlabeled data must come from the same distribution as your labeled data. If your labeled data is pictures of cats, and your unlabeled data is pictures of cars, SSL will hurt, not help.
Step-by-Step Workflow
Step 1: Partitioning Separate your data into three buckets:
- Labeled Train Set: The small “gold standard” set.
- Unlabeled Train Set: The large pool of raw data.
- Test Set: A distinct labeled set used only for final evaluation. Never use this for the SSL process.
Step 2: Choosing the Method
- For Tabular Data: Start with Self-Training or Label Spreading (available in Scikit-Learn). These are computationally cheap and often effective for structured data.
- For Images: Use FixMatch or MixMatch. These require deep learning frameworks (PyTorch/TensorFlow) but offer the best performance gains on visual data.
- For Text: Use UDA (Unsupervised Data Augmentation) or pre-trained language models (like BERT) fine-tuned with SSL objectives.
Step 3: Managing the “Warm-Up” SSL models can be unstable at the start because the model knows nothing. A common practice is to have a “warm-up” phase where you train only on the labeled data for a few epochs to get the model to a reasonable state before introducing the unlabeled data or increasing the weight of the unsupervised loss.
Step 4: Thresholding If using pseudo-labeling methods (like FixMatch), set a high confidence threshold (e.g., 0.95). Only use predictions above this threshold to train the model. This filters out noisy, uncertain guesses.
Tools and Libraries
You don’t always need to write SSL algorithms from scratch.
- Scikit-Learn: Provides SelfTrainingClassifier and LabelSpreading for non-deep learning tasks.
- PyTorch / TensorFlow: While they don’t have built-in “SSL Mode,” implementations of FixMatch, SimCLR, and Mean Teacher are widely available in open-source repositories like GitHub.
- USB (Unified SSL Benchmark): A library specifically designed to benchmark and implement various SSL algorithms in PyTorch.
5. Case Studies: Where SSL Shines
To understand the practical realism of these techniques, let’s look at how they are applied in industries where labels are scarce.
Scenario A: Drug Discovery
- The Problem: Identifying which chemical compounds will be active against a specific biological target. Wet lab experiments to label “active” vs. “inactive” are slow and costly.
- The Solution: Researchers have millions of unlabeled molecular structures. Using Graph Neural Networks (GNNs) in a semi-supervised setting, they leverage the structural information from the unlabeled molecules to improve the prediction of bioactivity on the few tested compounds.
- Result: Reduced time-to-candidate for new drugs and reduced experimental costs.
Scenario B: Audio Speech Recognition for Low-Resource Languages
- The Problem: We have massive labeled datasets for English or Mandarin, but very few for languages like Swahili or Quechua.
- The Solution: An SSL approach (like wav2vec) pre-trains on thousands of hours of unlabeled audio in the target language to learn the phonetic structure. It is then fine-tuned on the few hours of transcribed (labeled) audio available.
- Result: High-quality speech-to-text systems for languages that previously had no digital support.
Scenario C: Manufacturing Defect Detection
- The Problem: A factory line produces millions of perfectly good parts (unlabeled/negative class) and very rare defective parts. Getting humans to stare at streams of perfect parts to label them is inefficient.
- The Solution: An SSL model uses the abundance of normal data to learn a tight manifold of “normality.” It effectively combines anomaly detection with classification, using the few labeled defects to shape the boundary.
6. Common Mistakes and Pitfalls
Semi-supervised learning is delicate. If done incorrectly, it can degrade performance below that of a purely supervised model—a phenomenon known as performance degradation.
1. Distribution Mismatch
If your unlabeled data contains classes that are not present in your labeled data, the model can get confused.
- Example: You are building a dog classifier. Your labeled set is Poodles and Beagles. Your unlabeled set contains Poodles, Beagles, and Wolves. The model might incorrectly force the Wolves into the Poodle or Beagle categories, distorting the decision boundaries.
- Fix: Use Out-of-Distribution (OOD) detection techniques to filter the unlabeled data before feeding it to the SSL loop.
2. Confirming Your Own Bias
In self-training, if the model predicts a specific edge-case incorrectly with high confidence, it adds that error to the training set as a “truth.” The model then learns from its own error, becoming more confident in the wrong answer.
- Fix: Use Consistency Regularization. By forcing the model to agree on augmented versions of the input, you reduce the chance of it hallucinating a high-confidence label on a noisy image.
3. Hyperparameter Sensitivity
SSL adds new hyperparameters, such as the ratio of labeled to unlabeled data in a batch, the threshold for pseudo-labeling, and the weight of the unsupervised loss. These are often difficult to tune and can vary wildly between datasets.
- Fix: Do not assume default values from research papers will work on your custom dataset. Perform a grid search or Bayesian optimization specifically for the unsupervised loss weight.
7. Semi-Supervised vs. The Rest
To navigate the landscape effectively, it helps to distinguish SSL from its neighbors.
| Feature | Supervised Learning | Unsupervised Learning | Semi-Supervised Learning | Active Learning |
| Data Used | 100% Labeled | 100% Unlabeled | Small % Labeled + Large % Unlabeled | Small % Labeled + Human-in-the-loop |
| Goal | Prediction | Structure Discovery | Prediction | Efficient Annotation |
| Human Role | Labels everything upfront | Interprets results | Labels a seed set | Labels only what the model requests |
| Cost | High (Labeling) | Low | Moderate | Moderate (Iterative) |
- vs. Active Learning: In Active Learning, the model selects the most confusing unlabeled points and asks a human to label them. In SSL, the model tries to guess the label itself. Pro tip: These two are often combined. You can use SSL to label the easy stuff and Active Learning to query humans on the hard stuff.
- vs. Transfer Learning: Transfer learning takes a model trained on a different task (e.g., ImageNet) and fine-tunes it. SSL trains on the same task using unlabeled data from the same domain. Ideally, you use Transfer Learning to initialize your weights, and then SSL to refine them.
8. Deep Dive: Consistency Regularization (The Engine of Modern SSL)
Since Consistency Regularization is arguably the most successful modern technique, let’s break down how it works mathematically and conceptually without getting bogged down.
The core objective function in SSL usually looks like this:
Loss=Losssupervised+λ×Lossunsupervised
- Losssupervised: This is the standard Cross-Entropy loss calculated only on the labeled images. It ensures the model gets the known examples right.
- λ (Lambda): A weight that decides how much the model should care about the unlabeled data.
- Lossunsupervised: This is where the magic happens.
In methods like FixMatch, the unsupervised loss is calculated as follows:
- Take an unlabeled image x.
- Apply a weak augmentation (e.g., shift slightly) to get xweak.
- Apply a strong augmentation (e.g., heavy distortion, color cutout) to get xstrong.
- The model predicts the label for xweak. If the confidence is high, this becomes the target.
- The model predicts the label for xstrong.
- The Loss is the difference (distance) between the prediction on xstrong and the target derived from xweak.
The Intuition: By forcing the model to produce the same label for a clear image and a heavily distorted version of the same image, you force the model to ignore the noise (the distortion) and focus on the semantic object (the dog, the car, the tumor).
9. Future Directions
The field of SSL is moving rapidly. Current research is focusing on making these systems more robust and easier to deploy.
Open-Set SSL
Traditional SSL assumes the unlabeled data contains the same classes as the labeled data. “Open-Set” SSL is developing methods to handle “unknown” classes in the unlabeled data safely, ensuring the model essentially says “I don’t know” rather than forcing a wrong label.
Unified Foundation Models
With the rise of Large Language Models (LLMs) and Vision Transformers (ViTs), SSL is becoming implicit. Models like GPT-4 are trained on massive unsupervised datasets (text prediction) and then fine-tuned (supervised). The distinction between “Pre-training + Fine-tuning” and “Semi-Supervised Learning” is blurring, but the goal remains the same: leveraging the unlabelled masses.
Conclusion
Semi-supervised learning represents one of the most economically valuable shifts in artificial intelligence. It moves us away from the brute-force approach of “label everything” toward a more nuanced, human-like way of learning—where a few clear lessons enable us to make sense of a chaotic, unlabeled world.
For organizations drowning in data but starved for insights, SSL offers a lifeline. By implementing techniques like self-training or consistency regularization, you can boost model performance without breaking the bank on annotation.
Next Steps: If you have a dataset with partial labels, try benchmarking a standard supervised model against a simple self-training wrapper using Scikit-Learn. If you see gains, consider investing time in implementing a deep learning approach like FixMatch.
FAQs
1. Can semi-supervised learning work with very small labeled datasets? Yes, but there is a lower limit. You generally need enough labeled data to cover each class you want to predict (at least a few dozen per class). If the labeled set is too small, the model may experience “cold start” issues where the initial pseudo-labels are all wrong, leading the model astray.
2. Is semi-supervised learning better than supervised learning? Not necessarily “better,” but more efficient. If you have infinite labels, supervised learning will likely win or tie. SSL shines specifically when you have limited labels but abundant unlabeled data. It allows you to get “supervised-level” performance with a fraction of the labels.
3. What is the difference between Transductive and Inductive SSL? Inductive SSL builds a general model that can predict labels for new, unseen data (like a standard classifier). Transductive SSL focuses only on predicting the labels for the specific unlabeled points currently in your dataset, without necessarily creating a model that works on future data.
4. How much unlabeled data do I need? Typically, you want significantly more unlabeled data than labeled data to see benefits. Ratios of 1:10 or 1:100 (labeled to unlabeled) are common. If you only have a tiny amount of unlabeled data, the information gain might be negligible.
5. Does SSL require deep learning? No. While the most hype is around deep learning methods (like FixMatch), traditional algorithms like Label Propagation, Label Spreading, and Self-Training wrappers work perfectly well with SVMs, Random Forests, and Gradient Boosting machines on tabular data.
6. Can I use SSL for regression tasks? Yes. While classification is more common in literature, SSL techniques can be adapted for regression. For example, consistency regularization can enforce that the numerical output remains stable across augmentations of the input.
7. Why is my SSL model performing worse than my supervised model? This usually happens due to “distribution shift” (the unlabeled data is different from the labeled data) or “confirmation bias” (the model is learning from its own bad predictions). Try increasing the threshold for pseudo-labels or verifying that your unlabeled data is clean and relevant.
8. Is Transfer Learning the same as Semi-Supervised Learning? No. Transfer learning uses a model pre-trained on a different dataset (e.g., ImageNet). SSL uses unlabeled data from your target dataset. However, they are complementary; modern pipelines often use a pre-trained model (Transfer Learning) and then refine it using SSL on the specific task data.
References
- Zhu, X., & Goldberg, A. B. (2009). Introduction to Semi-Supervised Learning. Synthesis Lectures on Artificial Intelligence and Machine Learning. Morgan & Claypool Publishers.
- Chapelle, O., Schölkopf, B., & Zien, A. (2006). Semi-Supervised Learning. MIT Press.
- Sohn, K., Berthelot, D., Li, C. L., Zhang, Z., Carlini, N., Cubuk, E. D., … & Raffel, C. (2020). FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence. Advances in Neural Information Processing Systems (NeurIPS).
- Berthelot, D., Carlini, N., Goodfellow, I., Papernot, N., Oliver, A., & Raffel, C. (2019). MixMatch: A Holistic Approach to Semi-Supervised Learning. Advances in Neural Information Processing Systems (NeurIPS).
- Xie, Q., Dai, Z., Hovy, E., Luong, M. T., & Le, Q. V. (2020). Unsupervised Data Augmentation for Consistency Training. Advances in Neural Information Processing Systems (NeurIPS).
- Van Engelen, J. E., & Hoos, H. H. (2020). A survey on semi-supervised learning. Machine Learning, 109(2), 373-440.
- Google Research. (2020). Advancing Semi-Supervised Learning with FixMatch. Google AI Blog.
- Ouali, Y., Hudelot, C., & Tami, M. (2020). An Overview of Deep Semi-Supervised Learning. arXiv preprint arXiv:2006.05278.



















