In the modern era of artificial intelligence, data is often referred to as the “new oil.” However, in industries like healthcare and finance, this oil is heavily guarded, locked away in isolated silos, and protected by rigorous regulatory frameworks. The potential for AI to revolutionize disease diagnosis or financial fraud detection is immense, but the inability to pool sensitive data into a central repository often stifles progress. This is where federated learning for healthcare and finance emerges as a transformative solution.
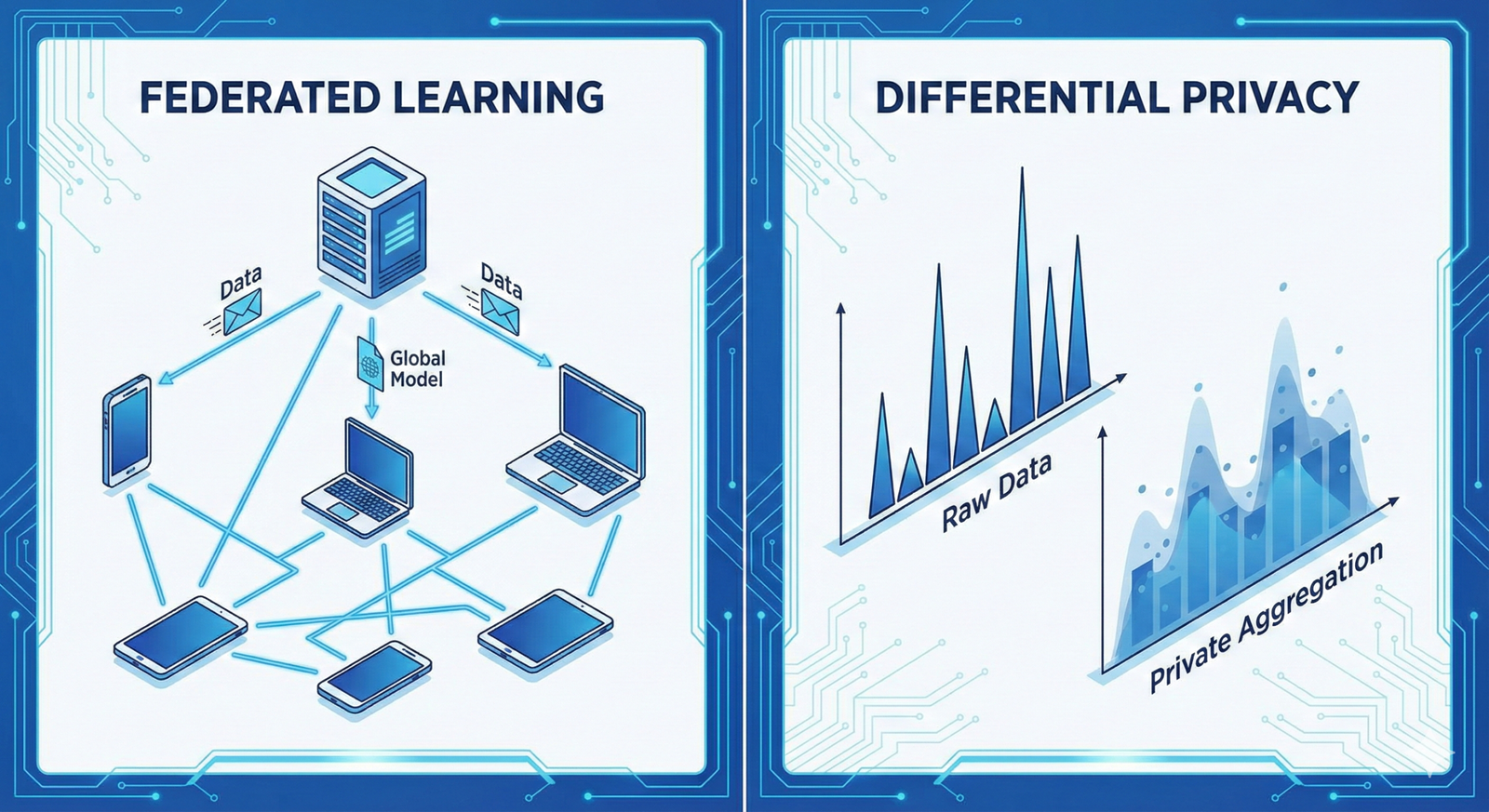
Federated Learning (FL) represents a paradigm shift in how machine learning models are trained. Instead of moving data to a central server—a practice fraught with privacy risks and regulatory hurdles—FL moves the model to the data. This decentralized approach allows institutions to collaborate on training powerful AI models without ever sharing the underlying raw data.
This comprehensive guide explores how federated learning is reshaping the landscape of high-stakes industries. We will examine the mechanics of the technology, its specific applications in medical and financial sectors, the privacy technologies that make it possible, and the practical challenges leaders face when implementing it.
Who this guide is for (and who it isn’t)
This guide is designed for:
- Data Scientists and AI Engineers looking to understand the architectural shifts required for decentralized training.
- CTOs and CISOs in healthcare and banking sectors evaluating privacy-preserving technologies.
- Policy Makers and Compliance Officers seeking to understand how AI collaboration can coexist with GDPR, HIPAA, and GLBA.
- Researchers interested in the intersection of cryptography and machine learning.
This guide is not for:
- Readers looking for a basic, non-technical definition of AI (we assume basic familiarity with machine learning concepts).
- Those seeking legal advice on specific compliance implementation (consult legal counsel for jurisdictional advice).
Key Takeaways
- Data stays local: The core tenet of federated learning is that raw data never leaves the device or institution; only model updates (gradients/weights) are shared.
- Silo breaking: FL allows competitors (banks) or isolated entities (hospitals) to build “super-models” that outperform what any single entity could build alone.
- Privacy is not automatic: While FL is privacy-preserving by design, it requires additional layers like differential privacy and secure multi-party computation to be truly robust against attacks.
- Regulatory alignment: FL aligns well with data minimization principles found in GDPR and HIPAA, making it a viable path for cross-border AI collaboration.
- High stakes: In healthcare, FL accelerates rare disease research; in finance, it creates stronger fraud detection networks without exposing customer transaction history.
1. The Data Paradox in Critical Industries
Healthcare and finance face a unique paradox. To build accurate, unbiased, and robust AI models, they require massive datasets that represent diverse populations and scenarios. However, they are also the custodians of the world’s most sensitive information—patient records and financial histories.
The Problem with Centralized Learning
Traditional machine learning is centralized. In a typical workflow, data is collected from edge devices or various institutions, uploaded to a central data lake or cloud server, cleaned, and then used to train a model.
For high-compliance industries, this approach presents critical failure points:
- Privacy Risks: Aggregating data creates a single point of failure. A breach at the central server exposes everything.
- Data Sovereignty: Laws like the GDPR in Europe or data residency laws in nations like India and China often forbid transferring data across borders.
- Competitive Secrets: Banks are unlikely to upload their proprietary transaction data to a shared server, even if it helps catch money launderers, for fear of leaking competitive intelligence.
- Network Latency: Transferring petabytes of medical imaging data is expensive and slow.
The Federated Solution
Federated learning in healthcare and finance flips this script. It enables “collaborative learning without data sharing.” By decoupling the ability to do machine learning from the need to store data centrally, it resolves the tension between data utility and data privacy.
2. How Federated Learning Works: The Mechanics
To understand the application, one must first grasp the architecture. Federated learning is not a single algorithm but a workflow for model training.
The Federated Lifecycle
As of early 2026, the standard lifecycle for a federated learning round involves four distinct steps:
- Global Model Distribution: A central server (the aggregator) initializes a global model and sends the current weights to selected client nodes (e.g., hospital servers or mobile banking apps).
- Local Training: Each client trains the model locally on its own private dataset. This process occurs entirely on the edge device or institution’s server. The raw data is accessed by the local training process but is never transmitted.
- Update Transmission: The clients generate a model update—usually a delta of the weights or gradients—indicating how the model improved based on their local data. This update is encrypted and sent back to the central server.
- Secure Aggregation: The central server averages (aggregates) the updates from all participating clients to create a new, improved global model. The cycle then repeats.
Types of Federated Learning
Depending on the data distribution, FL is categorized into three main types relevant to these industries:
- Horizontal Federated Learning: Used when datasets share the same feature space but different samples.
- Example: Two regional banks both have transaction data (same columns: date, amount, merchant) but different user bases. They collaborate to improve a fraud detection model.
- Vertical Federated Learning: Used when datasets share the same samples (users) but different feature spaces.
- Example: A bank and an e-commerce company share the same customers. The bank has credit history; the retailer has purchasing behavior. Vertical FL allows them to build a credit risk model without revealing their respective data columns to each other.
- Federated Transfer Learning: Applied when there is limited overlap in both samples and features, using transfer learning techniques to bridge the gap.
3. Federated Learning in Healthcare
Healthcare is arguably the most promising domain for federated learning. The fragmentation of medical data across hospitals, research centers, and countries hinders the development of AI models that generalize well across diverse demographics.
Breaking Down Medical Data Silos
Currently, a model trained on data from a hospital in Boston might perform poorly on patients in Bangalore due to demographic and genetic differences. Centralizing global data is legally and logistically impossible. Federated learning allows a model to “visit” hospitals around the world, learning from local populations without patient records ever leaving the premises.
Use Case 1: Medical Imaging and Diagnostics
AI models for radiology (MRI, CT scans, X-rays) require vast amounts of annotated images.
- The Scenario: Identifying early signs of glioblastoma (brain tumors).
- The Application: A consortium of 20 hospitals agrees to train a segmentation model. Instead of sending thousands of heavy MRI scans to a central cloud, the model travels to the hospitals.
- The Result: The model achieves state-of-the-art accuracy because it saw a wider variety of scanners, protocols, and patient anatomies than any single hospital possesses. This approach was famously validated by initiatives like the NVIDIA Clara ecosystem and the EXAM study during the COVID-19 pandemic.
Use Case 2: Drug Discovery and Development
Developing a new drug takes over a decade and costs billions. Predicting how a molecule interacts with biological targets is a data-heavy task.
- The Scenario: Pharmaceutical companies want to predict toxicity in new compounds to avoid costly failures in clinical trials.
- The Conflict: Pharma companies treat their molecular databases as highly confidential trade secrets. They will not share this data with competitors.
- The FL Solution: Using projects like the MELLODDY (Machine Learning Ledger Orchestration for Drug Discovery) consortium, competing pharma giants can train a shared predictive model. The model learns the physics of molecular interactions from everyone’s data, improving predictive power for all participants, without leaking the chemical structures of proprietary compounds.
Use Case 3: Rare Disease Research
For rare diseases, no single institution has enough patients to train a robust Deep Learning model.
- The Application: By federating the learning process across hundreds of specialized clinics globally, researchers can achieve a statistical significance that was previously impossible. This is critical for genomic analysis where privacy concerns are paramount because genomic data is inherently identifiable.
Case Example: Predicting Clinical Outcomes
Consider an Electronic Health Record (EHR) model designed to predict sepsis in ICU patients.
- Without FL: The model is trained on data from Hospital A. When deployed at Hospital B, it creates false alarms because Hospital B uses different lab equipment or operational protocols.
- With FL: The model learns to ignore site-specific noise (like the brand of a blood pressure monitor) and focus on universal physiological signals of sepsis, resulting in a robust, generalizable tool.
4. Federated Learning in Finance
The financial sector faces a dual pressure: sophisticated cybercrime requires collaborative defense, yet strict regulations (GLBA, GDPR, PCI-DSS) and fierce competition discourage data sharing.
Use Case 1: Fraud Detection
Fraud patterns evolve rapidly. If a fraud ring attacks Bank A, Bank B remains vulnerable until it encounters the same attack.
- The Application: A consortium of banks uses horizontal federated learning to train a fraud detection model.
- How it works: The model learns to recognize the patterns of fraudulent behavior (e.g., a specific sequence of rapid, small transactions followed by a large withdrawal) from Bank A. The weights associated with this pattern are aggregated into the global model. Bank B receives the update and can now detect this pattern instantly, even though it never saw the transaction data from Bank A.
- Benefit: The system creates a herd immunity effect against financial crime.
Use Case 2: Anti-Money Laundering (AML)
Money laundering is inherently a network problem; criminals move money between banks to hide its origin. A single bank only sees a slice of the transaction chain.
- The Challenge: Traditional AML generates massive false positives (often >95%) because banks lack context on the counter-party in a transaction.
- The FL Solution: Federated learning allows banks to collaboratively train models that identify complex laundering networks without violating bank secrecy laws. By analyzing the topology of transactions across institutions without revealing specific account holders, the AI can flag high-risk networks more accurately.
Use Case 3: Credit Risk Assessment
Lenders want to assess risk accurately to approve more loans while minimizing defaults.
- The Application: Vertical federated learning allows a lender to partner with utility companies or telecom providers.
- The Mechanism: The lender has payment history; the telecom provider has mobile usage stability data. They can collaboratively train a credit scoring model that uses the telecom data to boost prediction accuracy for “thin-file” customers (those with little credit history), enabling better financial inclusion. The telecom company never sees the loan details, and the bank never sees the call logs.
5. Privacy Technologies: The Defense Layer
It is a common misconception that Federated Learning is automatically private. While it prevents direct data leakage, sophisticated attacks can sometimes reverse-engineer raw data from model gradients (a process known as model inversion or reconstruction attacks).
To be truly secure for healthcare and finance, FL must be paired with privacy-enhancing technologies (PETs).
Differential Privacy (DP)
Differential privacy provides a mathematical guarantee of privacy. In the context of FL, “noise” is added to the model updates sent by the clients.
- How it works: Before sending the gradient to the central server, the local system adds random statistical noise. This noise is calibrated so that it masks the contribution of any single individual (patient or bank customer) but cancels out when thousands of updates are averaged, preserving the model’s utility.
- Trade-off: Adding too much noise protects privacy but degrades model accuracy. Finding the right “privacy budget” (epsilon) is a key engineering challenge.
Secure Multi-Party Computation (SMPC)
SMPC allows parties to compute a function over their inputs while keeping those inputs private.
- In FL: Secure Aggregation is a form of SMPC. It ensures that the central server sees only the final aggregated result of the model updates, not the individual updates from each hospital or bank.
- Analogy: Imagine three people want to know their average salary without revealing their individual salaries. They add random numbers to their salaries and share partial sums in a circle. The final calculation reveals the average, but no one knows what the others earn.
Homomorphic Encryption
This allows computation to be performed on encrypted data without decrypting it first.
- In FL: Clients encrypt their model updates. The central server aggregates these encrypted updates. The result is a new encrypted global model, which can only be decrypted by the clients. The server operates blindly, never seeing the mathematical values it is processing.
6. Technical Challenges and Pitfalls
Implementing federated learning in production environments is significantly more complex than centralized training.
Data Heterogeneity (Non-IID Data)
In centralized learning, you can shuffle data to ensure it is Independent and Identically Distributed (IID). In FL, data is generated locally and remains local.
- The Issue: A hospital in an elderly community will have vastly different data distributions than a pediatric clinic. A bank in London deals with different currency scales and spending habits than a rural cooperative.
- The Consequence: This statistical heterogeneity can cause the global model to fail to converge, or to be biased toward the clients with the most data (client drift).
- Mitigation: Techniques like FedProx (which limits how far a local model can deviate from the global model) are used to handle non-IID data.
Communication Bottlenecks
Deep learning models (like LLMs or heavy CNNs) can be gigabytes in size. Transmitting these models back and forth to thousands of edge devices creates a massive bandwidth strain.
- Mitigation: Model compression techniques, quantization (reducing the precision of the numbers), and pruning are essential to reduce the payload size during transmission.
Security: Poisoning Attacks
Since the central server cannot “see” the data, it cannot easily verify the integrity of the updates.
- Data Poisoning: A malicious actor (or a corrupted device) injects bad data into the local training set to corrupt the global model.
- Model Poisoning: A malicious client sends mathematically crafted updates designed to introduce a backdoor into the global model (e.g., creating a model that ignores fraud if the transaction amount is exactly $999.99).
- Defense: Robust aggregation algorithms (like Byzantine-tolerant aggregation) analyze the distribution of updates and reject statistical outliers that look suspicious.
7. Regulatory and Ethical Considerations
While FL helps with privacy, it introduces new governance questions.
GDPR and the “Right to be Forgotten”
Under GDPR, a user has the right to have their data deleted. In centralized AI, you delete the row in the database and retrain. In FL, the user’s data has effectively been “baked” into the model’s weights during a training round.
- The Challenge: Does a model update constitute personal data? If a user withdraws consent, how do you “unlearn” their contribution from the global model?
- Machine Unlearning: This is an active area of research focusing on how to mathematically remove the influence of specific data points from a trained model without retraining from scratch.
Bias and Fairness
If an FL model is trained mostly on data from wealthy hospitals with modern infrastructure, the global model may perform poorly for under-resourced clinics.
- The Risk: In finance, if the participating banks in a consortium serve primarily high-income demographics, the resulting credit risk model might unfairly penalize low-income applicants from non-participating institutions.
- Mitigation: Fairness-aware federated learning involves strictly monitoring the demographic distribution of participating nodes and weighing their contributions to ensure equitable representation.
8. Implementation Strategy: From Proof of Concept to Production
For organizations ready to adopt federated learning, the journey involves distinct phases.
Phase 1: Feasibility and Simulation
Before deploying to real devices, simulate the federated environment.
- Tools: Use frameworks like TensorFlow Federated (TFF), PySyft (OpenMined), or NVIDIA FLARE.
- Action: Partition your existing centralized data to mimic disjointed silos. Train a model using FL simulation and compare its accuracy against a centralized baseline.
Phase 2: Pilot with Trusted Partners
Do not start with 1,000 unknown devices. Start with a “Cross-Silo” setup.
- Setup: Connect 3–5 institutions (e.g., partner hospitals or branch offices).
- Infrastructure: Establish secure communication channels (TLS/SSL). Ensure all nodes have compatible hardware (GPU availability).
- Objective: Test the aggregation workflow and latency.
Phase 3: Privacy Hardening
Once the plumbing works, secure the water.
- Action: Integrate Differential Privacy and Secure Aggregation.
- Audit: Conduct penetration testing specifically targeting model inversion attacks.
Phase 4: Scaling and Lifecycle Management
- Orchestration: Use tools to manage the joining and leaving of nodes (handling dropouts is crucial—devices go offline constantly).
- Monitoring: Implement dashboards to track the convergence of the global model and the contribution quality of each node.
Conclusion
Federated learning is more than just a technical tweak; it is the architectural foundation for the next generation of collaborative AI in sensitive industries. For healthcare, it promises a future where medical insights are global, but patient data remains local. For finance, it offers a shield against systemic fraud while preserving the sanctity of customer privacy.
As of 2026, the technology has matured beyond academic curiosity into a viable enterprise solution. However, success requires a holistic approach that balances model accuracy with privacy budgets, addresses the statistical challenges of diverse data, and navigates the evolving regulatory landscape.
The organizations that master federated learning will be the ones that break down the walls of data silos, turning fragmented information into collective intelligence without compromising trust.
Next Steps
- Assess Data Readiness: Identify which datasets are currently siloed and evaluate their compatibility for federation.
- Select a Framework: Explore open-source tools like NVIDIA FLARE or TensorFlow Federated for initial prototyping.
- Legal Consultation: Engage compliance teams early to define the legal status of “model updates” within your specific jurisdiction.
FAQs
1. Is Federated Learning compliant with GDPR and HIPAA? Generally, yes, because it aligns with data minimization principles by keeping raw data local. However, it is not compliant by default. The model updates themselves can potentially be reverse-engineered to reveal personal data. Therefore, additional privacy measures like Differential Privacy must be implemented to ensure full compliance. Legal counsel should always review the specific architecture.
2. How does Federated Learning differ from Distributed Learning? In standard Distributed Learning, the data is usually centralized first, shuffled, and then distributed to worker nodes solely to speed up computation (parallelism). In Federated Learning, the data is inherently decentralized and never moves; the distribution is determined by the data source, not the system administrator, and the data is non-IID (not identical).
3. Does Federated Learning require special hardware? For “Cross-Silo” FL (server-to-server, like hospitals), standard enterprise GPUs are sufficient. For “Cross-Device” FL (smartphones, wearables), the training must be optimized for low-power processors (like ARM chips) and is usually done only when the device is plugged in and connected to Wi-Fi to preserve battery and data plans.
4. Can Federated Learning work with small datasets? Yes, that is often the point. While individual nodes might have small datasets that are insufficient for training deep learning models, aggregating updates from thousands of such nodes allows the creation of a high-quality global model.
5. What happens if a participating node has bad data? If a node has low-quality or mislabeled data, it can degrade the global model. Robust aggregation algorithms are designed to weigh contributions based on quality or data volume. Techniques like “Client Selection” can also help by only selecting nodes that meet certain data quality benchmarks for training rounds.
6. Is Federated Learning slower than centralized learning? Typically, yes. The communication overhead of sending model weights back and forth over the internet (often with high latency) makes the wall-clock time for training longer than training on a high-speed cluster in a single data center. However, it saves the time and legal effort required to move the data, which often makes the total project timeline shorter.
7. How much accuracy is lost in Federated Learning compared to centralized training? In ideal scenarios, FL can achieve accuracy near-identical to centralized training. However, in scenarios with highly heterogeneous (non-IID) data, there is often a slight performance trade-off. Advanced optimization algorithms are continuously narrowing this gap.
8. Who owns the global model in a federated learning consortium? This is a governance and contractual question, not a technical one. Usually, the entity orchestrating the central server owns the model, or it is shared via a consortium agreement. The governance framework must be established before training begins.
References
- McMahan, B., et al. (2017). Communication-Efficient Learning of Deep Networks from Decentralized Data. Google AI. Available at: https://arxiv.org/abs/1602.05629
- Rieke, N., et al. (2020). The future of digital health with federated learning. Nature Digital Medicine. Available at: https://www.nature.com/articles/s41746-020-00323-1
- Kaissis, G.A., et al. (2020). Secure, privacy-preserving and federated machine learning in medical imaging. Nature Machine Intelligence. Available at: https://www.nature.com/articles/s42256-020-0186-1
- NVIDIA Clara. (n.d.). Federated Learning for Healthcare. NVIDIA Developer Documentation. Available at: https://developer.nvidia.com/clara
- Yang, Q., et al. (2019). Federated Machine Learning: Concept and Applications. ACM Transactions on Intelligent Systems and Technology. Available at: https://dl.acm.org/doi/10.1145/3298981
- Kairouz, P., et al. (2021). Advances and Open Problems in Federated Learning. Foundations and Trends in Machine Learning. Available at: https://arxiv.org/abs/1912.04977
- MELLODDY Project. (2022). Machine Learning Ledger Orchestration for Drug Discovery. Official Project Overview. Available at: https://www.melloddy.eu/
- Bonawitz, K., et al. (2017). Practical Secure Aggregation for Privacy-Preserving Machine Learning. CCS ’17 Proceedings. Available at: https://dl.acm.org/doi/10.1145/3133956.3134012
- European Data Protection Supervisor (EDPS). (2023). TechDispatch #1: Federated Learning. Available at: https://edps.europa.eu/data-protection/our-work/publications/techdispatch/techdispatch-12023-federated-learning_en
- Li, T., et al. (2020). Federated Optimization in Heterogeneous Networks. SysML Conference. Available at: https://arxiv.org/abs/1812.06127