Choosing software today is less about brand names and more about strategy. The open source vs proprietary software question isn’t a binary either/or for modern organizations—it’s a portfolio decision that shapes your cost structure, security posture, innovation capacity, and risk profile. This article breaks down how to evaluate both options with a business lens, not just a technical one, so you can match the right model to the right use case.
Disclaimer: This article provides general information and is not legal, financial, or compliance advice. For licensing, contractual, accounting, and regulatory decisions, consult qualified professionals.
Key takeaways
- There’s no universal winner. The “better” option depends on use case, risk tolerance, compliance requirements, and team capabilities.
- Think in portfolios, not absolutes. Most businesses benefit from a blend of open source and proprietary tools aligned to value, risk, and control.
- Total cost of ownership matters more than sticker price. License fees are only one part of a multi-year cost model.
- Security is about process, not labels. Either model can be secure or insecure depending on how you manage updates, dependencies, and governance.
- Licensing and support are make-or-break. Understand obligations, upgrade paths, and service levels before you adopt—especially for customer-facing systems.
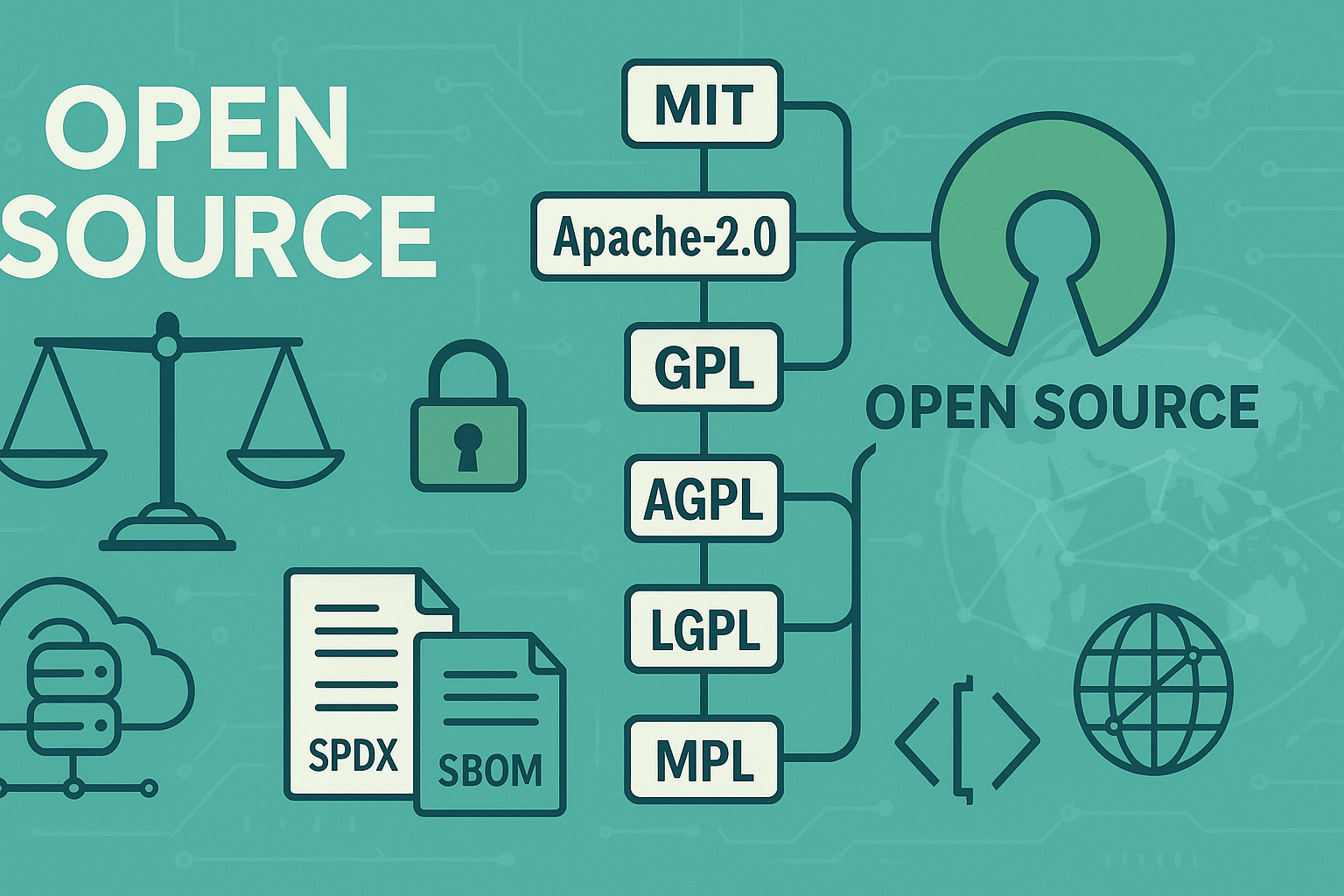
What “open source” and “proprietary” really mean for a business
What it is and core benefits/purpose
- Open source software (OSS) makes source code available under a license granting rights to use, modify, and redistribute. For businesses, OSS offers flexibility, cost control, and faster innovation through community and ecosystem effects.
- Proprietary software restricts access to source code and typically grants usage under a commercial license. For businesses, it often provides bundled support, predictable roadmaps, warranties, and clear accountability via contracts.
Requirements/prerequisites and low-cost alternatives
- If you lean open source: You’ll benefit from in-house technical capacity, basic license literacy, and a process for updates and dependency hygiene. Low-cost alternatives: managed distributions, vendor-backed builds, or cloud services that package OSS with support.
- If you lean proprietary: You’ll need budget for subscriptions/licenses and vendor management practices. Low-cost alternatives: tiered editions or SaaS plans that scale with usage.
Step-by-step implementation
- Inventory current and planned workloads. Classify by criticality, sensitivity, and compliance needs.
- Map capabilities to models. For adaptable, developer-heavy workloads, shortlist OSS. For regulated or specialized domains with strict SLAs, shortlist proprietary or vendor-supported OSS.
- Pilot, don’t pontificate. Run a proof of concept (PoC) with clear success criteria.
- Decide per component. It’s common to use OSS infrastructure and proprietary SaaS for specialized business apps.
- Lock in governance. Establish update, support, and licensing policies before production.
Beginner modifications and progressions
- Start small: Adopt OSS for non-critical tooling (e.g., CI, observability) or pick a proprietary SaaS for a single department.
- Progress: Expand to core systems as you mature support processes, or renegotiate proprietary contracts as usage stabilizes.
Recommended frequency/duration/metrics
- Review portfolio quarterly for cost, performance, and incident metrics.
- Track adoption KPIs: time to value, mean time to recover from incidents, upgrade latency, and user satisfaction.
Safety, caveats, and common mistakes
- Treat “free” as “free like a puppy,” not “free like a beer.” OSS needs care and feeding.
- Don’t assume proprietary equals hands-off. You still own integration, configuration, and operational resilience.
Mini-plan (example)
- Pick one OSS and one proprietary candidate for the same problem.
- Run a two-week pilot for each against identical test datasets and load.
- Compare TCO assumptions, performance, and operational overhead; choose with eyes open.
Cost and total cost of ownership (TCO)
What it is and core benefits/purpose
TCO captures the full cost over time—licenses or subscriptions, infrastructure, support, staff time, training, downtime risk, and migration/exit costs. The purpose: avoid optimizing for the wrong line item.
Requirements/prerequisites and low-cost alternatives
- A simple spreadsheet model and basic financial literacy are sufficient.
- Low-cost alternative: start with a one-year cash model, then layer multi-year assumptions as you learn.
Step-by-step implementation
- Define a 3–5 year horizon. Include growth and change assumptions.
- Model five buckets: acquisition, operate, support, risk, and exit.
- Quantify assumptions: hours for upgrades, training cycles, expected incident counts, and likely professional services.
- Stress-test scenarios: best case, expected, and worst case (e.g., major version upgrade).
- Compare apples to apples: Standardize seat counts, transaction volumes, or CPU hours across options.
Beginner modifications and progressions
- Beginner: estimate only the largest costs (license vs engineer time).
- Advanced: incorporate depreciation, chargebacks, and risk-adjusted downtime costs.
Recommended frequency/duration/metrics
- Reforecast semi-annually.
- Metrics: cost per user/transaction, cost per feature shipped, and variance from plan.
Safety, caveats, and common mistakes
- Underestimating human time on upgrades and migrations.
- Ignoring exit costs for proprietary tools or hidden integration costs for OSS.
Mini-plan (example)
- Create a TCO template with the five cost buckets.
- Populate with three scenarios per option.
- Present to finance and engineering leadership for decision.
Security and risk management
What it is and core benefits/purpose
Security posture depends on update velocity, vulnerability management, and operational discipline. Open source offers transparency and rapid community fixes; proprietary offers vendor accountability and contractual security commitments. Either can be excellent—or poor—depending on process.
Requirements/prerequisites and low-cost alternatives
- Establish basic secure development and operations practices: code scanning, dependency tracking, patching cadence, and incident response.
- Low-cost alternative: use managed platforms that bundle scanners and SBOM generation.
Step-by-step implementation
- Adopt a secure development framework. Define controls for build, test, release, and deploy.
- Track dependencies. Maintain an SBOM for critical services and automate vulnerability alerts.
- Set patch SLAs. Define acceptable windows by severity and exposure.
- Run tabletop exercises. Practice handling a critical vulnerability with comms and rollback plans.
- Verify suppliers. For proprietary vendors and OSS maintainers, review security documentation, release notes, and update histories.
Beginner modifications and progressions
- Beginner: start with monthly dependency checks and critical-only patching.
- Progress: move to automated, continuous scanning and risk-based patch pipelines.
Recommended frequency/duration/metrics
- Weekly dependency scans; monthly rollups.
- Metrics: time to update, vulnerability backlog, percentage of services with current SBOMs, and failed build rate due to security gates.
Safety, caveats, and common mistakes
- Assuming transparency equals security, or that secrecy equals safety.
- Deferring patches because of fear of breakage—test and roll forward instead.
Mini-plan (example)
- Generate an SBOM for a critical service.
- Identify top five vulnerable dependencies and patch within a week.
- Add a release gate that fails builds on severe known issues.
Licensing and compliance
What it is and core benefits/purpose
Licensing dictates rights and obligations. OSS licenses range from permissive (e.g., permissive family like MIT-style) to copyleft (e.g., strong-reciprocity families) that require sharing modifications under certain conditions. Proprietary licenses set usage limits, warranties, support terms, and restrictions. The purpose is to avoid surprises—particularly in redistribution, SaaS scenarios, or embedding software in products.
Requirements/prerequisites and low-cost alternatives
- Basic license literacy and an internal policy that defines which licenses are allowed, restricted, or prohibited.
- Low-cost alternative: adopt a community license policy template and adjust minimally with counsel.
Step-by-step implementation
- Create a license policy. Define allowed OSS licenses and standard vendor terms.
- Implement scanning. Integrate automated license scanning in CI for all builds.
- Track obligations. For copyleft or network-copyleft components, document how you satisfy notice, source offer, or attribution.
- Review vendor terms. Check usage caps, data handling, audit clauses, and indemnities in proprietary contracts.
- Educate teams. Teach engineers when a distribution or network use triggers obligations.
Beginner modifications and progressions
- Beginner: whitelist widely used permissive licenses and block unknowns pending review.
- Progress: maintain a centralized component registry with approved versions and notices.
Recommended frequency/duration/metrics
- Quarterly audits of license compliance on top services.
- Metrics: percentage of builds passing license checks, number of exceptions, and time to resolve license issues.
Safety, caveats, and common mistakes
- Treating all open source as “public domain.” Licenses are legal instruments.
- Over-restricting to avoid risk and locking out valuable components. Balance is key.
Mini-plan (example)
- Add a license scanner to your CI for one repository.
- Fix flagged notices and create a template NOTICE file.
- Expand the scanner to all critical services.
Customization, flexibility, and innovation pace
What it is and core benefits/purpose
Customization is your ability to shape software to fit your processes rather than bend processes to fit software. Open source shines when unique workflows differentiate your business. Proprietary excels when standardization reduces complexity, especially with mature feature sets and integrations.
Requirements/prerequisites and low-cost alternatives
- For deep customization: engineering capacity, plugin architecture literacy, and change management.
- Low-cost alternative: prefer configuration over customization; pick tools with strong APIs and extension points.
Step-by-step implementation
- Document differentiators. Identify where your process truly creates advantage.
- Choose a customization path. Decide between configuration, plugins, or forks.
- Establish contribution guidelines. If you modify OSS, upstream what you can to reduce fork maintenance.
- Budget for lifecycle. Plan for maintaining extensions through upgrades.
Beginner modifications and progressions
- Beginner: start with configuration and small plugins.
- Progress: contribute upstream or maintain a light fork with a clear merge policy.
Recommended frequency/duration/metrics
- Review extensions per major release.
- Metrics: upgrade effort hours, divergence from upstream, number of custom patches.
Safety, caveats, and common mistakes
- Forks become technical debt if you can’t keep pace with upstream.
- Over-customizing proprietary tools via scripts that break on upgrades.
Mini-plan (example)
- Replace a custom script with a supported plugin.
- Submit a small enhancement upstream to reduce local patching.
- Create an internal upgrade playbook including plugin tests.
Support, reliability, and SLAs
What it is and core benefits/purpose
Support is your safety net. Proprietary vendors typically offer contractual SLAs, response times, and escalation paths. Open source support ranges from community channels to paid subscriptions with enterprise SLAs. Reliability stems from architecture, operations, and vendor/maintainer maturity.
Requirements/prerequisites and low-cost alternatives
- Define required SLAs by system criticality.
- Low-cost alternative: managed services for popular OSS stacks that come with support.
Step-by-step implementation
- Classify systems by impact. Map criticality tiers to support requirements.
- Evaluate support options. Compare vendor SLAs, community responsiveness, release cadence, and roadmap transparency.
- Set escalation runbooks. Who to call, when, and how to roll back.
- Test the promise. Open tickets during pilot to gauge real response quality.
Beginner modifications and progressions
- Beginner: accept best-effort community support for non-critical tools.
- Progress: add paid support for anything customer-facing or revenue-impacting.
Recommended frequency/duration/metrics
- Quarterly vendor reviews.
- Metrics: incident MTTR, SLA breach count, support satisfaction.
Safety, caveats, and common mistakes
- Confusing a popular community with guaranteed support.
- Buying premium support you never use—right-size to need.
Mini-plan (example)
- Define SLA targets for each critical system.
- Map current tools to support models and identify gaps.
- Close gaps via subscription or vendor change.
Integration and ecosystem fit
What it is and core benefits/purpose
Software rarely lives alone. The right choice plays well with your existing identity, data, automation, and monitoring stack. Open source often leads on open standards and extensibility; proprietary vendors may offer polished integrations and certified connectors.
Requirements/prerequisites and low-cost alternatives
- A clear integration map: identity, data flows, events, and APIs.
- Low-cost alternative: use iPaaS connectors or open APIs to bridge gaps.
Step-by-step implementation
- List must-have integrations. Identity, logging, billing, data warehouse, messaging.
- Prototype key flows. Test a couple of critical end-to-end journeys before you commit.
- Check version compatibility. Especially with SDKs and drivers.
- Define change control. Avoid breaking changes by pinning versions and staging upgrades.
Beginner modifications and progressions
- Beginner: prioritize tools with native connectors to your top three platforms.
- Progress: standardize on event schemas and contract tests.
Recommended frequency/duration/metrics
- Monthly review of integration errors.
- Metrics: integration failure rate, connector coverage, mean time to fix.
Safety, caveats, and common mistakes
- Ignoring data egress costs and latency.
- Overlooking API rate limits and pagination behavior.
Mini-plan (example)
- Map one product’s data pipeline from source to analytics.
- Prototype the pipeline with both an OSS and proprietary option.
- Choose based on throughput, stability, and operational overhead.
Performance and scalability
What it is and core benefits/purpose
Performance is the system’s ability to meet latency and throughput targets under load. Scalability is how costs and performance evolve as usage grows. Open source may give you tuning freedom and horizontal scale at infra cost; proprietary may give you optimized engines, autoscaling, and performance guarantees.
Requirements/prerequisites and low-cost alternatives
- Load testing tools, realistic datasets, and performance dashboards.
- Low-cost alternative: sample synthetic workloads before building full test rigs.
Step-by-step implementation
- Define SLOs. Explicit latency/throughput targets at given volumes.
- Run comparative load tests. Reproduce peak and failure scenarios.
- Instrument and tune. Optimize indexes, caches, and concurrency settings.
- Review cost curves. Measure spend per unit of throughput.
Beginner modifications and progressions
- Beginner: test only the critical endpoints that drive customer experience.
- Progress: simulate failure modes (node loss, network partitions).
Recommended frequency/duration/metrics
- Major test per release; spot checks monthly.
- Metrics: p95 latency, error rate, cost per transaction.
Safety, caveats, and common mistakes
- Testing on unrealistic data sizes or shapes.
- Ignoring cold start, cache warmup, and backup windows.
Mini-plan (example)
- Capture a day of anonymized production traffic.
- Replay against two candidate systems with the same SLO.
- Pick the option with best cost/performance and least operational risk.
Business size and industry fit: patterns that work
Small and growing businesses
- Favor tools with quick time-to-value and minimal administration.
- OSS is great for standard infrastructure and developer tooling; proprietary SaaS often wins for finance, HR, and CRM to reduce overhead.
Mid-market organizations
- Mix and match. Use OSS to avoid lock-in on platforms that differentiate (data, analytics, integration). Use proprietary where support and integrations are critical.
Enterprises and regulated sectors
- Demand clear contracts, auditability, and long-term support.
- Choose vendor-backed OSS or enterprise proprietary products for mission-critical workloads, and maintain open standards to preserve exit options.
Step-by-step implementation
- Set strategy per domain: infrastructure, data, apps, and enablement.
- Decide preferred model by domain based on risk and uniqueness.
- Enforce via reference architectures and procurement guardrails.
Safety and caveats
- Beware of “religious” choices. Optimize per domain and keep escape hatches open.
Mini-plan (example)
- Write a one-page policy: which domains prefer OSS vs proprietary.
- Align procurement and architecture review to that policy.
- Revisit annually based on market shifts and lessons learned.
Implementation guide: from evaluation to rollout
What it is and core benefits/purpose
A structured decision and rollout process reduces surprises. The benefit is a repeatable, defensible approach that balances speed with due diligence.
Requirements/prerequisites and low-cost alternatives
- Cross-functional team: engineering, security, legal, finance, and operations.
- Low-cost alternative: a lightweight working group with a single decision template.
Step-by-step implementation
- Define the outcome. Write crisp success criteria and SLOs.
- Shortlist contenders. Include at least one OSS and one proprietary option.
- Run PoCs with the same script. Data, load, and test cases must match.
- Score with a weighted matrix. Weight cost, security, performance, support, and integration.
- Select and negotiate. For proprietary, secure SLAs and price protections. For OSS, plan support and upgrade cadence.
- Plan the migration. Data, cutover, rollback, and communication.
- Harden operations. Monitoring, backup, disaster recovery, and changecontrol.
- Review post-launch. Compare outcomes against your success criteria.
Beginner modifications and progressions
- Beginner: keep the matrix simple (5–7 criteria).
- Progress: extend with risk scoring and exit cost analysis.
Recommended frequency/duration/metrics
- Use this process for every net-new platform and major renewal.
- Metrics: evaluation lead time, number of surprises post-launch, and variance versus planned TCO.
Safety, caveats, and common mistakes
- Skipping legal review for OSS obligations.
- Over-customizing during PoC and underestimating operational costs.
Mini-plan (example)
- Build a one-page evaluation brief with goals and constraints.
- Score two options with a simple matrix; pick a winner.
- Plan a staged rollout with a rollback path.
Quick-start checklist
- Define success criteria and SLOs for the problem you’re solving.
- Inventory existing tools and integration dependencies.
- Shortlist both an OSS and proprietary candidate.
- Build a 3–5 year TCO model with at least three scenarios.
- Run a time-boxed PoC with identical workloads.
- Set patch and upgrade policies before production.
- Confirm licensing obligations and support SLAs.
- Plan exit paths: backups, data exports, configuration portability.
Troubleshooting and common pitfalls
“We chose on license cost and now maintenance is eating us alive.”
Revisit TCO with realistic engineer hours and upgrade cycles. Adjust staffing or consider a managed distribution.
“Security flagged unknown dependencies after go-live.”
Automate SBOM generation and dependency checks in CI/CD. Set patch SLAs and include them in the definition of done.
“The vendor integration doesn’t behave like the demo.”
Prototype critical flows early with production-like data. Insist on a proof-of-value milestone before signing multi-year deals.
“Our fork drifted too far from upstream.”
Reduce local patches, upstream changes where possible, and assign a maintainer responsible for merge discipline.
“We can’t meet audit requirements.”
Enable logging, access reviews, and change tracking. Establish a control map from policy to evidence artifacts.
How to measure progress or results
- Value delivery: lead time for new features, time to onboard a team, user satisfaction.
- Reliability: uptime, incident frequency, mean time to restore service.
- Security: patch latency, vulnerability backlog, build failures on security gates.
- Cost: variance vs planned TCO, cost per transaction/user.
- Governance: percentage of services with SBOMs, license compliance pass rate, SLA adherence.
A simple 4-week starter plan
Week 1 — Define and shortlist
- Clarify the business outcome and SLOs.
- Identify one OSS and one proprietary candidate.
- Draft a TCO template and list must-have integrations.
Week 2 — Pilot and assess
- Run PoCs with identical datasets and load.
- Prepare a risk register: security, compliance, and operational risks.
- Start an SBOM for the pilot service and enable basic monitoring.
Week 3 — Decide and plan
- Score options with a weighted matrix and agree on a selection.
- For proprietary: negotiate price protections, SLAs, and exit clauses.
- For OSS: confirm support plan, upgrade cadence, and contribution policy.
Week 4 — Prepare for production
- Finalize migration plan, rollback steps, and communications.
- Document license obligations and create NOTICE/readme templates.
- Schedule the first post-launch review and define success metrics.
FAQs
1) Is open source really “free” for businesses?
The license may be free, but you’ll pay in time, expertise, infrastructure, and support. Model multi-year costs before deciding.
2) Which is more secure: open source or proprietary?
Neither is inherently safer. Security depends on patch velocity, dependency hygiene, and operational rigor.
3) Can I use open source in a commercial product?
Yes, but you must comply with the license. Some licenses allow broad use with minimal obligations; others require sharing modifications under certain conditions.
4) What if I don’t have in-house engineers?
Consider vendor-backed OSS distributions or proprietary SaaS with strong SLAs. You can still benefit from openness without building everything yourself.
5) How do I avoid vendor lock-in?
Prefer open standards, exportable data formats, and APIs. Negotiate exit clauses and keep configuration as code where possible.
6) How do I evaluate support quality?
Open tickets during the pilot and measure response and resolution times. Ask for references and review release cadences.
7) What’s the best approach for regulated industries?
Use a risk-based approach with explicit control mapping. Consider vendor-backed OSS or enterprise proprietary products that provide audit artifacts.
8) How do I keep up with updates without breaking things?
Adopt staged rollouts, semantic version pinning, and automated tests. Schedule regular maintenance windows.
9) When should I fork open source?
Only when necessary and with a plan to minimize divergence. Prefer plugins or upstream contributions to reduce long-term burden.
10) Can I mix open source and proprietary in the same stack?
Absolutely. Many successful stacks use OSS for infrastructure and proprietary SaaS for specialized business applications.
11) Do I need a formal license policy?
Yes. A simple policy that defines allowed, restricted, and prohibited licenses will save time and reduce legal risk.
12) What’s the single most important metric to watch?
Track time to update critical vulnerabilities. It’s a leading indicator of both risk and operational maturity.
Conclusion
“Open source vs proprietary” is not a contest to crown a universal champion. It’s a strategic choice you make repeatedly—per domain, per workload, and per stage of growth. When you evaluate through the lens of cost over time, security processes, licensing obligations, integration fit, and support reality, you’ll usually land on a blended portfolio that gives you control where it matters and simplicity where it pays.
Copy-ready CTA: Choose one system today, run a two-week A/B pilot with identical workloads, and make a decision grounded in data—not assumptions.
References
- Open Source Definition, Open Source Initiative, https://opensource.org/osd
- GNU General Public License, Version 3, Free Software Foundation, 2007-06-29, https://www.gnu.org/licenses/gpl-3.0.en.html
- GNU Affero General Public License, Version 3, Free Software Foundation, 2007-11-19, https://www.gnu.org/licenses/agpl-3.0.en.html
- Apache License, Version 2.0, The Apache Software Foundation, 2004-01, https://www.apache.org/licenses/LICENSE-2.0
- MIT License, Choose a License, https://choosealicense.com/licenses/mit/
- Secure Software Development Framework (SSDF) SP 800-218, National Institute of Standards and Technology, 2022-02, https://csrc.nist.gov/pubs/sp/800/218/final
- Supply-chain Levels for Software Artifacts (SLSA), slsa.dev, https://slsa.dev/
- ISO/IEC 5230: OpenChain Standard Overview, OpenChain, https://www.openchainproject.org/standard
- The impact of open source software and hardware on technological independence, competitiveness and innovation in the EU economy, European Commission, 2021, https://digital-strategy.ec.europa.eu/en/library/impact-open-source-software-and-hardware-technological-independence-competitiveness-and-innovation-eu-economy
- Software Bill of Materials (SBOM), Cybersecurity and Infrastructure Security Agency, https://www.cisa.gov/sbom