The integration of artificial intelligence into the healthcare sector is no longer a futuristic concept—it is a present reality. However, as of March 2026, the primary hurdle remains the safe and ethical use of sensitive patient information. “Training agents on clinical data” involves a complex intersection of machine learning, legal compliance, and medical ethics. This roadmap is designed to navigate the technical and regulatory nuances of building AI agents that are both powerful and private.
Key Takeaways
- Compliance is Mandatory: Adhering to HIPAA (USA) and GDPR (EU) is the baseline; “Privacy by Design” is the gold standard.
- De-identification is Not Enough: Simple masking of names is insufficient for modern AI; structural and statistical privacy (like Differential Privacy) are required.
- Architecture Matters: Choosing between Retrieval-Augmented Generation (RAG) and Fine-tuning has massive implications for data leakage risks.
- Human-in-the-Loop: Clinical agents must be validated by medical professionals to prevent “hallucinations” that could impact patient safety.
Who This Is For
This guide is written for Chief Technology Officers (CTOs), healthcare data scientists, compliance officers, and clinical researchers who are tasked with building or deploying Large Language Models (LLMs) and autonomous agents within hospital systems, pharmaceutical companies, or health-tech startups.
Safety Disclaimer: The information provided in this article is for educational and informational purposes only. It does not constitute legal or medical advice. Always consult with a qualified legal professional regarding HIPAA/GDPR compliance and a medical board for clinical validation of AI tools.
Understanding the Landscape of Clinical AI Agents
In the context of modern medicine, an “agent” is an AI system capable of reasoning, using tools, and making decisions based on data. Unlike simple chatbots, clinical agents might assist in diagnosing rare diseases, summarizing longitudinal patient records, or optimizing drug discovery pipelines.
To make these agents effective, they must be trained on or have access to “Proprietary Clinical Data.” This includes Electronic Health Records (EHR), medical imaging (DICOM files), genomic sequences, and physician notes. This data is the lifeblood of medical progress, but it is also Protected Health Information (PHI).
The Risks of Training on PHI
When we talk about training agents on clinical data, the greatest risk is data leakage. LLMs have shown a tendency to “memorize” rare sequences in their training sets. If an agent is trained on un-redacted patient notes, a clever user might be able to prompt the model to reveal a patient’s specific diagnosis or identity.
Phase 1: The Regulatory and Compliance Foundation
Before a single line of code is written, you must establish a legal fortress. As of March 2026, regulatory scrutiny on AI in healthcare has reached an all-time high.
HIPAA and the “Safe Harbor” Method
In the United States, the Health Insurance Portability and Accountability Act (HIPAA) dictates how PHI must be handled. To use clinical data for training, it must either be:
- De-identified via the Safe Harbor method (removing 18 specific identifiers).
- Authorized by the patient (rarely feasible for large-scale training).
- Determined by a statistical expert to have a “very small” risk of re-identification.
SOC 2 and HITRUST
If you are a vendor providing AI services to hospitals, your infrastructure must be SOC 2 Type II compliant and, ideally, HITRUST certified. These frameworks ensure that your data centers, encryption protocols, and employee access controls meet the highest security standards.
Phase 2: Data Engineering and Privacy-Preserving Techniques
Once the legal framework is set, the data must be prepared. This is where most projects succeed or fail.
Advanced De-identification
Modern clinical agents require “unstructured” data—the free-text notes written by doctors. Redacting these is difficult because a patient’s identity might be hidden in a narrative description (e.g., “The patient is the mayor of [Small Town]”).
You must use Named Entity Recognition (NER) models specifically trained on medical corpora to identify and scrub:
- Names, dates, and locations.
- Social security numbers and medical record numbers.
- Biometric identifiers.
- Unique photographic images.
Synthetic Data Generation
One of the most promising trends in March 2026 is the use of Synthetic Data. Instead of training on real patients, you train a generative model to create “fake” patients that share the same statistical properties as the real ones. This allows you to train agents without ever exposing real PHI to the final model weights.
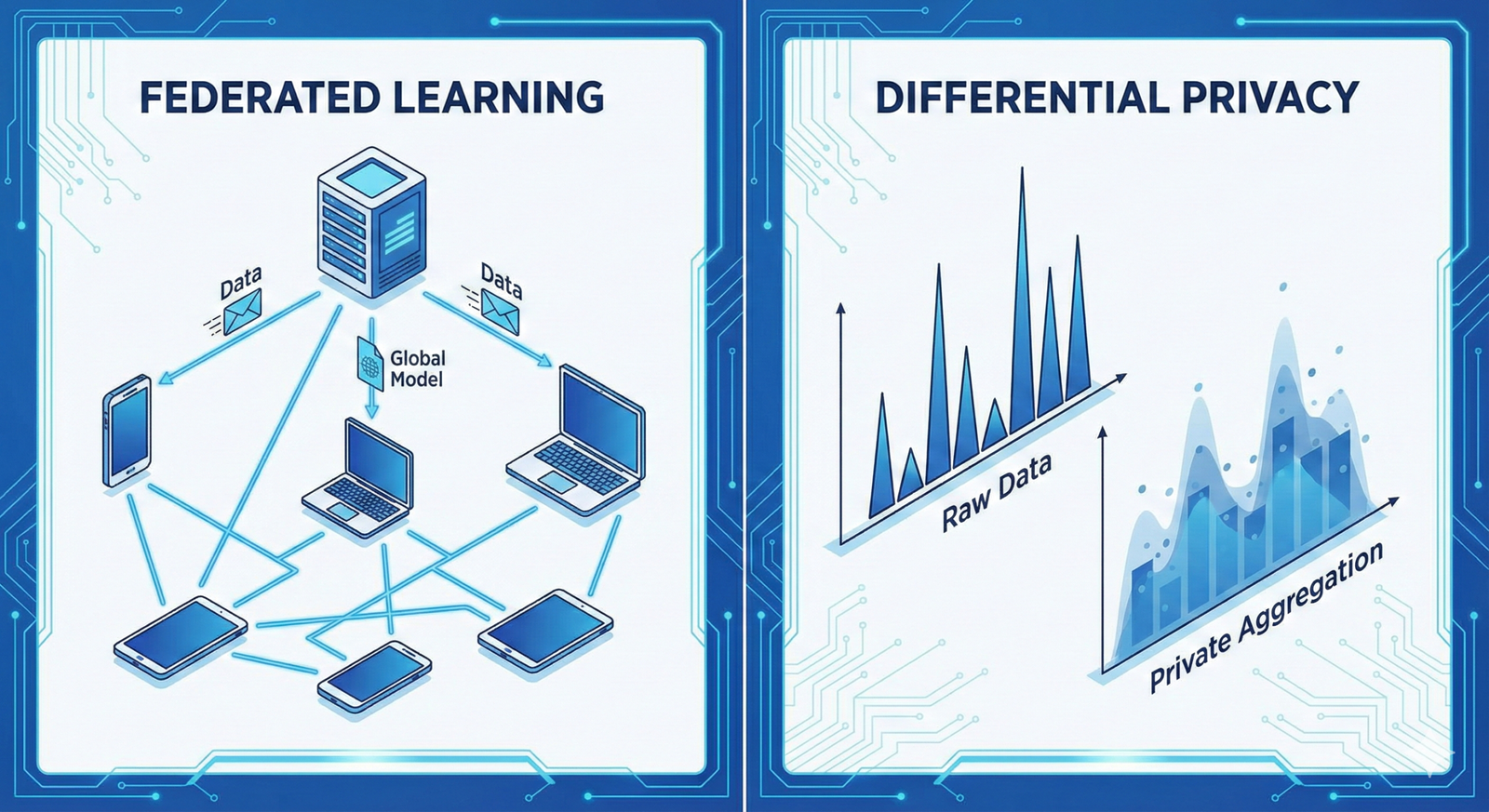
Differential Privacy (DP)
Differential Privacy adds “mathematical noise” to the data or the model’s gradients during training. This ensures that the presence or absence of any single individual in the training set does not significantly change the outcome of the model.
- The Epsilon ($\epsilon$) Parameter: This measures the “privacy budget.” A lower $\epsilon$ means higher privacy but potentially lower model accuracy. Finding the “sweet spot” is the primary task of the healthcare AI engineer.
Phase 3: Architecture Selection—RAG vs. Fine-Tuning
How you integrate the data into the agent determines your privacy roadmap.
1. Fine-Tuning (The “Weight-Memory” Approach)
Fine-tuning involves updating the actual weights of the AI model using clinical data.
- Pros: The agent gains deep “intuition” for medical terminology and specific institutional styles.
- Cons: Extremely high risk of data leakage. Once data is in the weights, it is very hard to “unlearn.”
- Privacy Strategy: Use Differential Privacy Stochastic Gradient Descent (DP-SGD).
2. Retrieval-Augmented Generation (RAG)
RAG keeps the data in a secure, encrypted database. When a query comes in, the agent looks up relevant (and redacted) snippets and uses them to formulate an answer.
- Pros: Data never enters the model’s permanent memory. You can revoke access to specific documents instantly.
- Cons: The agent is limited by the quality of the search/retrieval mechanism.
- Privacy Strategy: Use a “Privacy-Preserving Vector Database” with end-to-end encryption.
Phase 4: Federated Learning—The “Data Stays Home” Model
For many institutions, moving data to a central server is a deal-breaker. Federated Learning allows you to train agents on clinical data without the data ever leaving the hospital’s firewall.
How it Works:
- A “base model” is sent to five different hospitals.
- Each hospital trains the model locally on its own private EHR data.
- The hospitals send only the “model updates” (mathematical gradients) back to a central server.
- The central server averages these updates to create a smarter “global model.”
- The global model is sent back to the hospitals.
This approach is the “holy grail” of clinical AI because it respects data sovereignty while allowing for large-scale learning.
Phase 5: The Roadmap to Deployment
Step 1: Data Audit and Inventory
Map every point where PHI enters your system. Identify “High-Risk” data types (Psychiatry notes, HIV status, etc.) that may require extra layers of encryption or exclusion.
Step 2: Implementation of a Secure Enclave
Use Trusted Execution Environments (TEEs) like AWS Nitro Enclaves or Azure Confidential Computing. These allow you to process data in a “black box” where even the cloud provider cannot see the contents.
Step 3: Red-Teaming for Privacy
Before launch, hire “Ethical Hackers” to perform Inference Attacks. They will try to trick your agent into revealing the training data. If they can extract a patient’s name, your roadmap needs a detour.
Step 4: Human-in-the-Loop (HITL) Validation
Every output of a clinical agent should be subject to a “Reasonability Check.” In March 2026, the most successful implementations use a two-tiered system:
- AI Agent: Suggests a treatment plan.
- Human Physician: Reviews and signs off.
- Feedback Loop: The physician’s corrections are used to further refine the agent (using privacy-preserving methods).
Common Mistakes When Training Clinical Agents
- Over-reliance on Anonymization: Thinking that removing a name makes data “safe.” Re-identification through “linkage attacks” (combining medical data with public social media data) is a major threat.
- Ignoring Metadata: DICOM images often contain patient names and dates embedded in the file headers, even if the image itself is blurred.
- The “Black Box” Fallacy: Assuming that because an LLM is complex, the data inside it is hidden. LLMs are surprisingly “leaky” without explicit privacy safeguards.
- Neglecting Vendor Risk: Using a third-party API (like OpenAI or Anthropic) without a Business Associate Agreement (BAA). Without a BAA, you are in direct violation of HIPAA.
Conclusion: The Path Forward for Medical AI
Training agents on clinical data is a high-stakes endeavor that requires more than just technical prowess; it requires a deep commitment to patient trust. As we move further into 2026, the distinction between “good AI” and “great AI” will be defined by privacy.
The roadmap provided here—focusing on regulatory alignment, advanced de-identification, architectural choice, and federated systems—offers a sustainable path. By treating privacy not as a hurdle, but as a core feature, healthcare organizations can unlock the immense potential of AI to save lives while honoring the sacred privacy of the patient-provider relationship.
Next Steps for Your Team:
- Conduct a Privacy Impact Assessment (PIA): Evaluate your current data pipeline against the 18 HIPAA identifiers.
- Evaluate RAG vs. Fine-tuning: Determine if your use case truly requires model weight updates or if a secure retrieval system is sufficient.
- Draft a BAA: If you are using cloud providers, ensure your Business Associate Agreements are signed and up-to-date for 2026 standards.
Would you like me to generate a specific Data Governance Checklist tailored for your organization’s internal audit?
FAQs
1. Is it legal to train AI on patient data if it’s de-identified?
Yes, under HIPAA, “de-identified” data is no longer considered PHI and is not subject to the same restrictions. However, the de-identification must be rigorous (Safe Harbor or Expert Determination). Under GDPR, you still need a “legal basis” (like public interest or scientific research) even for pseudonymized data.
2. Can I use OpenAI’s GPT-4 for clinical data?
Only if you are using an Enterprise version that provides a Business Associate Agreement (BAA) and ensures that your data is not used to train their global models. Never put PHI into a standard, consumer-facing ChatGPT interface.
3. What is the biggest technical challenge in this roadmap?
The “Privacy-Utility Trade-off.” As you increase privacy (e.g., adding more noise via Differential Privacy), the model’s accuracy tends to decrease. Finding the level of privacy that satisfies legal requirements without making the agent useless is the primary engineering challenge.
4. How does “Federated Learning” differ from “Cloud Training”?
In cloud training, all data is moved to a central server. In Federated Learning, the data stays on the local hospital servers, and only mathematical updates are shared. This significantly reduces the risk of a massive data breach.
5. What happens if my AI agent “hallucinates” a patient’s record?
This is a significant risk. If an agent hallucinates a diagnosis, it’s a safety issue; if it hallucinates a real person’s name into a fake record, it’s a privacy issue. This is why Human-in-the-Loop (HITL) validation is mandatory.
References
- U.S. Department of Health & Human Services (HHS): Guidance on Methods for De-identification of PHI
- NIST (National Institute of Standards and Technology): AI Risk Management Framework 1.0
- Journal of Medical Internet Research (JMIR): Privacy-Preserving AI in Healthcare: A Review
- Nature Medicine: Federated Learning for Predicting Clinical Outcomes
- GDPR Official Text: Article 89: Safeguards for Scientific Research
- HIMSS (Healthcare Information and Management Systems Society): AI in Healthcare Security Standards
- ISO/IEC 27001: Information Security Management Systems
- The Lancet Digital Health: Clinical Validation of AI Models