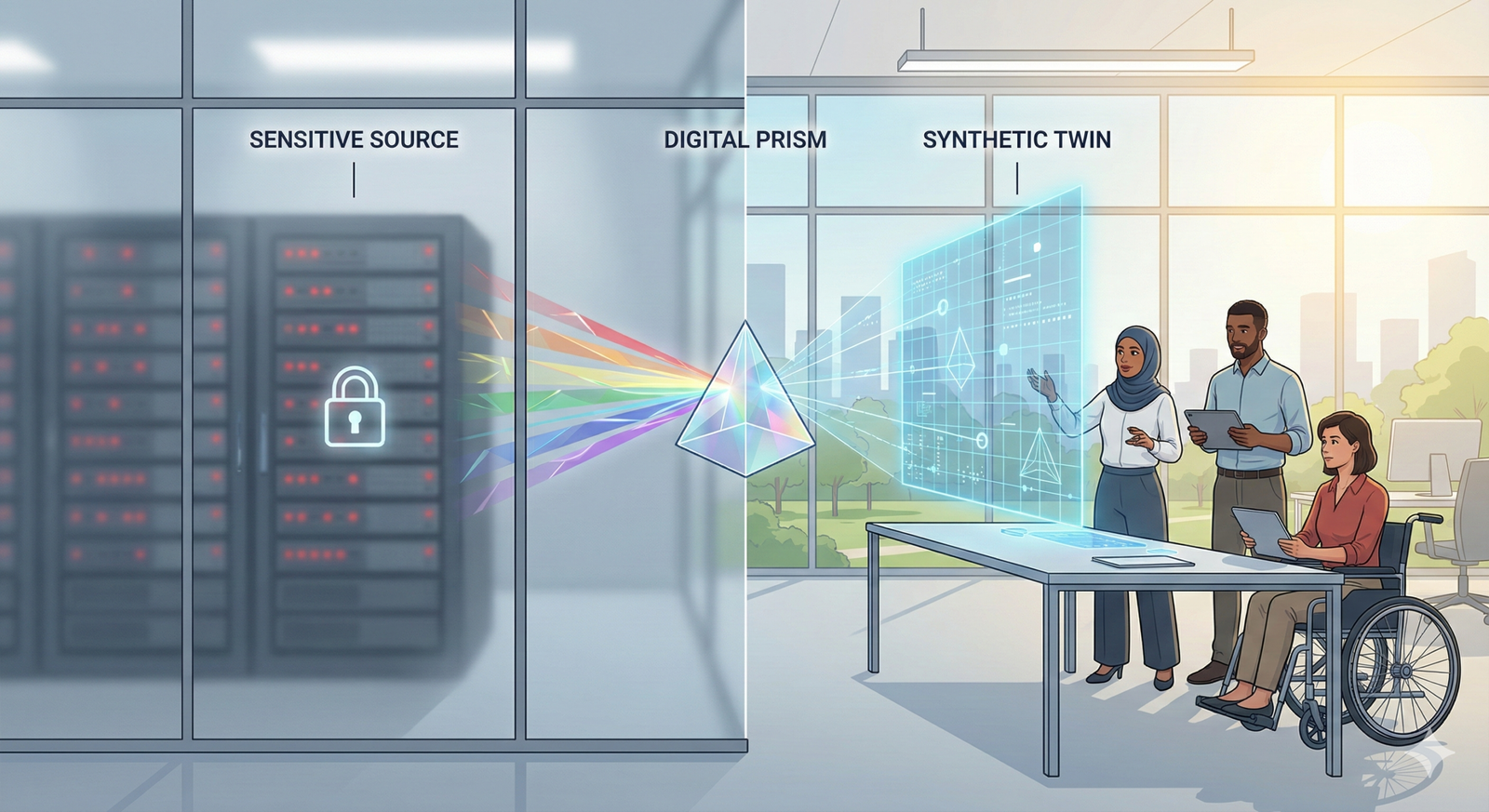
In the modern data economy, organizations face a paradoxical challenge: they need vast amounts of high-fidelity data to train accurate machine learning (ML) models, yet strict privacy regulations and ethical obligations make accessing that data increasingly difficult. This is the “data utility vs. data privacy” deadlock. Synthetic data for privacy—artificially generated data that retains the statistical properties of the original dataset without containing any real individual’s information—has emerged as the primary solution to break this deadlock.
As of January 2026, synthetic data is no longer just an experimental technique; it is a cornerstone of enterprise AI strategy. From healthcare researchers modeling disease progression without viewing patient records to financial institutions detecting fraud without exposing transaction logs, synthetic data is reshaping how we build models.
This guide provides a comprehensive overview of synthetic data for privacy-preserving model training. We will explore the underlying mechanisms, the trade-offs between fidelity and privacy, the regulatory landscape, and the practical steps to implement a synthetic data pipeline.
Key Takeaways
- Definition: Synthetic data is computer-generated data that mirrors the statistical patterns of real-world data but contains no Personal Identifiable Information (PII).
- Double Utility: It allows organizations to share data internally or externally for model training while significantly reducing compliance risks (GDPR, CCPA/CPRA).
- The Trade-off: There is an inherent tension between privacy and utility; “perfect” privacy often degrades model performance, while “perfect” utility increases re-identification risk.
- Mechanisms: Modern generation relies on advanced techniques like Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Large Language Models (LLMs).
- Compliance: While safer than anonymization, synthetic data is not automatically compliant; it must be evaluated for leakage and re-identification risks.
Scope: What this guide covers
In this guide, “synthetic data” refers to fully synthetic datasets generated from real seed data for the purpose of training analytical or machine learning models (tabular, text, or image). We will focus on privacy preservation as the primary objective. We will not cover synthetic data used purely for software testing (e.g., generating random strings to test field limits) or data generated solely for artistic purposes (e.g., AI art).
1. What is Synthetic Data in the Context of Privacy?
To understand synthetic data for privacy, we must first distinguish it from traditional data protection methods. For decades, organizations relied on anonymization or de-identification. This involved masking names, suppressing outliers, or aggregating values (e.g., changing age “34” to “30-40”).
However, research has repeatedly shown that traditional anonymization is brittle. In high-dimensional datasets (datasets with many columns or features), it is often possible to “re-identify” individuals by cross-referencing the anonymized data with public datasets—a process known as a linkage attack.
Synthetic data takes a fundamentally different approach. Instead of modifying the original records, synthetic data generation involves learning the probability distribution of the original data and then sampling new, artificial records from that learned distribution.
The “Digital Twin” Concept
Think of your real dataset as a population of people. Traditional anonymization puts masks on their faces. Synthetic data, conversely, studies the crowd to understand the demographics (age distribution, height, clothing styles) and then creates a simulation of a new crowd. The new crowd looks like the old one, behaves like the old one, and has the same statistical relationships (e.g., taller people tend to wear larger shoes), but no specific person from the original crowd exists in the simulation.
Because there is no 1:1 mapping between a synthetic record and a real person, the risk of re-identification is drastically reduced. This allows data scientists to train models on the “digital twin” data that perform almost as well as models trained on real data.
Types of Synthetic Data
- Fully Synthetic: The dataset contains no original data. Every record is generated from scratch based on the learned model. This offers the highest privacy protection.
- Partially Synthetic: Only sensitive attributes (e.g., income, diagnosis) are synthesized, while non-sensitive attributes (e.g., demographic region, generic dates) are kept real. This is riskier and less common for high-privacy needs.
- Hybrid/Augmented: Synthetic data is mixed with real data to upsample rare events (e.g., fraud cases) while maintaining privacy for the majority class.
2. Why Privacy-Preserving Model Training Matters Now
The demand for synthetic data is driven by a convergence of regulatory pressure, technical bottlenecks, and ethical imperatives.
The Regulatory Vise
As of early 2026, the regulatory landscape regarding AI and data privacy has matured significantly.
- GDPR (Europe): The General Data Protection Regulation imposes strict limits on data processing. Using real customer data for model training often requires explicit consent or a legitimate interest justification that is hard to sustain for experimental R&D. Synthetic data, if properly generated (i.e., truly non-identifiable), can sometimes fall outside the scope of GDPR personal data, freeing it for use.
- AI Act (EU): The EU AI Act emphasizes data governance and bias mitigation. Synthetic data allows teams to balance datasets (e.g., adding more synthetic records for underrepresented groups) to comply with fairness requirements without needing to harvest more intrusive real-world data.
- CCPA/CPRA (California) & US State Laws: Similar to GDPR, these laws grant consumers rights over their data. Deleting a user’s data from a training set is complex; deleting it from the generator and regenerating the synthetic set is often cleaner.
The Data Silo Problem
In large enterprises, data is often trapped in silos. The marketing team cannot access the finance team’s transaction data due to internal access controls. This prevents the training of holistic models (e.g., predicting churn based on both web activity and spending habits). Synthetic data acts as a “safe shareable format.” The finance team can generate a synthetic version of their transaction logs and share it with marketing. The marketing team can train a model on this synthetic data without ever seeing a real customer’s bank balance.
Third-Party Collaboration
Innovation often requires external partners—vendors, cloud providers, or academic researchers. Sending real patient data or proprietary financial records to a third party is a massive security risk and legal headache. Sharing a synthetic dataset allows organizations to leverage external expertise without exposing their core assets or their customers’ secrets.
3. How Synthetic Data Generation Works
Generating high-quality synthetic data for privacy is not as simple as using random number generators. It requires sophisticated machine learning models that can capture complex, non-linear correlations between variables.
Generative Adversarial Networks (GANs)
GANs remain one of the most popular architectures for generating synthetic data, particularly for images and complex tabular data. A GAN consists of two neural networks competing against each other:
- The Generator: Tries to create fake data that looks real.
- The Discriminator: Tries to distinguish between the real data and the fake data created by the Generator.
During training, the Generator gets better at fooling the Discriminator, and the Discriminator gets better at spotting fakes. Eventually, the Generator produces data so realistic that the Discriminator cannot tell the difference.
Variational Autoencoders (VAEs)
VAEs are another class of generative models. They work by compressing the input data into a lower-dimensional representation (encoding) and then trying to reconstruct the original data from that representation (decoding). By sampling from the “latent space” of the compressed representation, VAEs can generate new data points that are similar to the original inputs but not identical. VAEs are often more stable to train than GANs and are excellent for tabular data.
Large Language Models (LLMs) for Text
For unstructured data like customer support chats, medical notes, or emails, Large Language Models (LLMs) are the standard. By fine-tuning an LLM on a private corpus of text, the model learns the vocabulary, syntax, and domain-specific context. It can then generate new text documents that maintain the semantic meaning of the original corpus. Note: Privacy with LLMs is tricky because LLMs can “memorize” specific training examples. Techniques like Differential Privacy (discussed below) are essential here to prevent the LLM from regurgitating real PII verbatim.
Statistical Methods (Bayesian Networks)
For simpler tabular datasets, or when explainability is paramount, Bayesian networks are used. These models map the probabilistic dependencies between columns (e.g., if “Smoker” is True, the probability of “Lung Cancer” increases). They are computationally efficient and offer transparency, as the graph structure explicitly shows how variables influence each other.
4. The Privacy-Utility Trade-off
This is the central challenge of synthetic data.
- Utility (Fidelity): How closely does the synthetic data mimic the real data? If you train a model on synthetic data, will it predict real-world outcomes accurately?
- Privacy: How distinct is the synthetic data from the real data? Can an attacker infer real attributes from the synthetic set?
There is generally an inverse relationship between these two.
- High Utility, Low Privacy: If the Generator overfits, it essentially copies the real data. The model trained on it works perfectly, but privacy is compromised.
- High Privacy, Low Utility: If the Generator introduces too much noise or randomness to protect identities, the correlations break. A model trained on this data will fail to detect subtle patterns (e.g., a fraud detection model might miss complex fraud rings).
The Role of Differential Privacy (DP)
To mathematically guarantee privacy, practitioners often combine synthetic data generation with Differential Privacy (DP). DP adds a calibrated amount of noise to the learning process (specifically, to the gradients or the parameters of the model). It guarantees that the output (the synthetic dataset) does not depend significantly on the presence or absence of any single individual in the training set.
- Epsilon (ϵ): This is the “privacy budget.” A lower ϵ means more noise and higher privacy (but lower utility). A higher ϵ means less noise and better utility (but higher privacy risk). Finding the “Goldilocks” zone—where ϵ is low enough to satisfy privacy experts but high enough to train useful models—is the art of modern data synthesis.
5. Assessing the Quality of Synthetic Data
Before using synthetic data for model training, you must validate it. Trusting a “black box” generator is dangerous. Validation should cover three pillars: Fidelity, Utility, and Privacy.
A. Fidelity Metrics (Statistical Similarity)
These metrics measure how well the distributions match.
- Univariate Distributions: Do the histograms of individual columns (e.g., Age, Income) match?
- Bivariate Correlations: Does the correlation matrix of the synthetic data look like the real one? If Age and Income are positively correlated in real life, they must be in the synthetic data too.
- Hellinger Distance / Jensen-Shannon Divergence: Statistical measures that quantify the distance between two probability distributions. A score near 0 indicates high similarity.
B. Utility Metrics (Model Performance)
This is the “Train on Synthetic, Test on Real” (TSTR) evaluation.
- Train a model (e.g., Random Forest) on the Synthetic data.
- Train the same model architecture on the Real data.
- Test both models on a held-out Real test set.
- Compare: If the Synthetic-trained model achieves 95% of the accuracy/F1-score of the Real-trained model, the synthetic data has high utility.
C. Privacy Metrics (Leakage Assessment)
These metrics quantify the risk of re-identification.
- Distance to Closest Record (DCR): Measures the distance between each synthetic record and its nearest neighbor in the real dataset. If the distance is zero, the generator has memorized and regurgitated a real record (a privacy breach).
- Membership Inference Attack (MIA) Simulation: Try to train an attacker model to guess whether a specific real individual was used to train the generator. If the attacker succeeds better than random guessing, privacy is low.
- Attribute Inference Risk: Even if a whole record isn’t copied, can an attacker who knows columns A and B (e.g., Zip Code and Age) predict sensitive column C (e.g., Diagnosis) with high confidence using the synthetic data?
6. Use Cases by Industry
Synthetic data is sector-agnostic, but its impact is most profound in regulated industries.
Healthcare and Life Sciences
- Scenario: A hospital wants to build a model to predict sepsis onset in ICU patients.
- Challenge: HIPAA and GDPR prevent sharing patient vitals and history with cloud AI vendors or external researchers.
- Solution: The hospital generates a high-fidelity synthetic dataset of patient journeys.
- Outcome: Researchers develop the model on synthetic data. The final model is then shipped back to the hospital and fine-tuned/validated on real data behind the hospital’s firewall (a technique often paired with Federated Learning).
Financial Services (FinTech)
- Scenario: A bank wants to detect a new type of money laundering pattern.
- Challenge: Real fraud examples are rare (imbalanced data) and highly sensitive (financial secrecy).
- Solution: The bank uses synthetic data to upsample the fraud class, generating thousands of realistic “synthetic fraud” examples based on the few real ones they have.
- Outcome: The fraud detection model becomes more robust because it has seen more variations of the fraud pattern during training, without exposing real client IBANs.
Retail and E-commerce
- Scenario: A retailer wants to optimize supply chain logistics based on customer purchase history.
- Challenge: Purchase history is personal data.
- Solution: Generate synthetic transaction logs.
- Outcome: Supply chain analysts can model demand spikes and inventory needs without ever knowing who bought what.
Autonomous Vehicles
- Scenario: Training self-driving cars to recognize pedestrians in snowstorms.
- Challenge: Gathering real video footage of dangerous conditions is risky and expensive.
- Solution: Use game engines and generative AI to create synthetic video feeds of pedestrians in snow, rain, and fog.
- Outcome: The computer vision model improves safety features without putting real test drivers or pedestrians in harm’s way. (Note: This is “simulation-based” synthetic data, distinct from privacy-preserving tabular synthesis, but the principle of model training remains).
7. Implementation Workflow: A Step-by-Step Guide
How does an organization actually deploy this? Here is a standard workflow.
Step 1: Define Scope and Requirements
- Data Type: Is it tabular, time-series, or text?
- Use Case: Is it for software testing (low fidelity ok) or ML training (high fidelity required)?
- Privacy Level: Is the data for internal use (medium privacy) or public release (maximum privacy)?
Step 2: Data Preprocessing
Clean the real “seed” data. Remove extreme outliers that might confuse the generator or that are so unique they compromise privacy. Handle missing values and normalize data formats.
Step 3: Select the Generator Model
- For simple tables: Bayesian Networks or Gaussian Copulas.
- For complex, multi-table databases: GANs or VAEs designed for relational data.
- For sequential data (time-series): Recurrent Neural Networks (RNNs) or specialized Time-GANs.
Step 4: Training and Generation
Train the generator on the seed data. Monitor the loss functions to ensure the model is converging (learning) but not overfitting (memorizing). Once trained, generate a sample equal to or larger than the original dataset.
Step 5: Validation (The Loop)
Run the Fidelity, Utility, and Privacy checks (Section 5).
- If Privacy is too low: Increase Differential Privacy noise (ϵ) or reduce model capacity. Retrain.
- If Utility is too low: Check for mode collapse (where the model only produces one type of record). Adjust hyperparameters or switch architectures. Retrain.
Step 6: Deployment
Release the synthetic dataset to the data science team. Tag the metadata clearly so users know it is synthetic and understand any limitations (e.g., “This data underrepresents rural demographics compared to reality”).
8. Tools and Frameworks
Organizations can choose between open-source libraries and commercial platforms.
Open Source Libraries
These are excellent for experimentation and small-scale projects.
- SDV (Synthetic Data Vault): A Python library ecosystem that offers multiple models (CTGAN, Gaussian Copula) for single-table, multi-table, and time-series data.
- SmartNoise: A differential privacy library co-developed by Microsoft and Harvard’s OpenDP, useful for integrating DP into the generation process.
- Gretel Synthetics (Open Source components): Provides libraries for generating synthetic text and structured data, often utilizing RNNs and Transformers.
Commercial Platforms
For enterprise scale, support, and validated privacy audits, commercial tools are often preferred.
- Vendor capabilities to look for: Look for automated privacy reports, support for relational databases (maintaining referential integrity across tables), and “connector” integrations with major cloud data warehouses (Snowflake, Databricks).
- Commercial vendors often provide indemnification or certification that their generation process meets specific standards (like ISO/IEC 27001 or specific GDPR interpretations), which open-source libraries do not.
9. Common Mistakes and Pitfalls
Even with the best tools, projects can fail.
1. The “Privacy Theater” Trap
Assuming that because data is synthetic, it is automatically private.
- Reality: If a GAN overfits, it can output a record that is 99% identical to a real person. You must run privacy attacks against your own data to verify safety.
2. Ignoring Bias Amplification
Generative models tend to pick up on majority patterns and ignore minority patterns (a phenomenon called “mode collapse” or “bias amplification”).
- Risk: If your real data has 90% men and 10% women, the synthetic data might drift to 95% men and 5% women, making the bias worse.
- Fix: Actively monitor for representation bias and use re-balancing techniques during generation.
3. Breaking Referential Integrity
In relational databases (e.g., Users table linked to Orders table), synthetic data must preserve the logic.
- Failure: Generating a synthetic “Order” for a “User ID” that doesn’t exist in the synthetic Users table.
- Fix: Use multi-table synthesis tools that understand foreign keys and schema constraints.
4. Expecting Perfection
Synthetic data is rarely 100% as good as real data for training complex models.
- Reality: Expect a small performance drop (e.g., 2-5% drop in accuracy). The trade-off is that you get access to data you otherwise couldn’t use at all. A model with 90% accuracy is better than no model because the data was locked away.
10. Alternatives to Synthetic Data
Synthetic data is not the only privacy-enhancing technology (PET).
| Technology | How it Works | Pros | Cons |
| Synthetic Data | Generates new data based on learned patterns. | Shareable, high flexibility, debugging is easy. | Can hallucinate artifacts; strict privacy verification needed. |
| Federated Learning | Trains the model locally on devices/silos; sends only weight updates to a central server. | Data never leaves the source; good for mobile/edge. | High technical complexity; communication overhead; harder to debug data issues. |
| Homomorphic Encryption | Performs computations on encrypted data without decrypting it. | Mathematically secure; data remains encrypted during processing. | Extremely slow (computationally expensive); currently impractical for training large ML models. |
| Trusted Execution Environments (TEEs) | Processes data in a hardware-protected “enclave.” | Hardware-level isolation. | Requires specific hardware; trust is placed in the chip manufacturer. |
Verdict: Synthetic data is often the most versatile entry point because it results in a tangible dataset that data scientists can view, query, and manipulate using standard tools (Pandas, SQL), whereas Federated Learning and Homomorphic Encryption require specialized infrastructure and workflows.
11. Future Trends in Privacy-Preserving AI
As we look toward the remainder of the decade, several trends are solidifying.
- Generative AI for Structured Data: The transformer architecture (which powers ChatGPT) is increasingly being adapted for tabular data (e.g., TabPFN, GReaT). These models show promise in capturing semantic relationships in data better than older GAN architectures.
- Regulation of Synthetic Data: We anticipate specific guidance from bodies like the European Data Protection Board (EDPB) specifically clarifying the legal status of synthetic data—moving from ambiguity to codified standards.
- Automated Privacy Audits: “Privacy Ops” will become a standard CI/CD step. Just as code is tested before deployment, synthetic data pipelines will have automated adversarial attacks run against them to certify privacy scores before the data is released to downstream teams.
Conclusion
Synthetic data for privacy-preserving model training represents a critical maturation in the field of Data Science. It transitions the industry from a “collect and lock down” mentality to a “learn and generate” approach. By decoupling the information (patterns, correlations, insights) from the identity (the specific individuals), synthetic data allows innovation to proceed without compromising human rights.
For organizations, the path forward is clear: start small. Pick a low-risk, high-friction use case—perhaps a dataset that takes weeks to get approval for access. Implement a synthetic data pilot, validate the privacy-utility curve, and demonstrate that a model trained on the “digital twin” yields actionable results. In 2026, the ability to synthesize data is not just a technical skill; it is a competitive advantage in the race to build responsible, robust AI.
Next Steps for Practitioners
- Audit your data access bottlenecks: Identify where your data science teams are waiting on data due to privacy concerns.
- Experiment with open source: Use a library like SDV to generate a synthetic version of a public dataset to understand the workflow.
- Define your risk tolerance: Engage with your legal/compliance team early to define what “acceptable risk” looks like for your organization (e.g., defining acceptable re-identification scores).
FAQs
1. Is synthetic data completely anonymous?
Not automatically. While synthetic data does not contain real individuals, it can inadvertently “memorize” unique outliers if the generation model is overfitted. It is only considered “anonymous” or “non-identifiable” after it passes rigorous privacy tests (like distance-to-nearest-neighbor checks) to ensure no real record can be reconstructed or inferred from the synthetic set.
2. Can I use synthetic data to comply with GDPR?
Yes, but with caveats. If the synthetic data is generated using a privacy-preserving process that guarantees no re-identification is possible (often requiring Differential Privacy), it may no longer be considered “personal data” under GDPR. This frees it from many processing restrictions. However, the process of creating it (processing the original real data) still falls under GDPR.
3. Does training on synthetic data reduce model accuracy?
Usually, yes, but the gap is closing. In most practical applications, models trained on high-quality synthetic data achieve 90% to 98% of the performance of models trained on real data. This small drop in accuracy is often an acceptable trade-off for the ability to access and share the data freely.
4. How does Differential Privacy relate to synthetic data?
Differential Privacy (DP) is a mathematical definition of privacy. In synthetic data generation, DP is often used as a constraint during the training of the generator (e.g., DP-GAN). It ensures that the generated data does not reveal whether any specific individual was part of the original training set, providing a provable privacy guarantee.
5. Can synthetic data replace real data entirely?
For training, often yes. For final validation, usually no. Most organizations train and iterate on synthetic data but perform a final “gold standard” validation on a secure, real dataset before deploying the model to production. This ensures that any artifacts introduced by the synthesis process do not cause unexpected failures in the real world.
6. Is synthetic data the same as “mock data”?
No. Mock data is typically random or rule-based data used for software testing (e.g., “Field A must be an integer”). It does not preserve statistical correlations. Synthetic data uses machine learning to learn the actual patterns and distributions of the real world, making it suitable for analytics and model training, which mock data is not.
7. What happens if the real data is biased?
The synthetic data will also be biased. If your real hiring dataset discriminates against a certain demographic, the synthetic generator will learn and reproduce that discrimination. However, synthetic data generation offers a unique opportunity to fix this by re-sampling or constraining the generator to produce a more balanced dataset (“fairness-aware synthesis”).
8. How much real data do I need to create synthetic data?
You need enough data for the generative model to learn the distributions. For a simple tabular dataset, a few thousand rows might suffice. For complex images or high-dimensional data, you may need tens of thousands of records. If the seed dataset is too small, the generator may simply memorize the data rather than learning generalizable patterns.
9. Can I reverse-engineer the real data from the synthetic data?
If the synthetic data is generated correctly, no. The goal is to make this mathematically impossible (or computationally infeasible). However, if the generator is poorly trained (overfitted), a “membership inference attack” might reveal that a specific person was in the original dataset, or a “model inversion attack” might reconstruct specific features. This is why privacy metrics are mandatory.
10. Who owns the copyright to synthetic data?
This is a complex legal area and varies by jurisdiction. Generally, since the data is machine-generated and does not represent real individuals, it is often viewed as the intellectual property of the entity that performed the generation. This avoids the “data rights” issues associated with using customer data, but users should consult local IP laws.
References
- NIST (National Institute of Standards and Technology). (2023). Differential Privacy Synthetic Data Challenge Results and Technical Reports. Retrieved from https://www.nist.gov/
- European Data Protection Supervisor (EDPS). (2021). TechDispatch #3: Synthetic Data. Retrieved from https://edps.europa.eu/
- Jordon, J., Yoon, J., & van der Schaar, M. (2018). PATE-GAN: Generating Synthetic Data with Differential Privacy Guarantees. International Conference on Learning Representations (ICLR).
- Google Research. (2025). TensorFlow Privacy: Library for training machine learning models with differential privacy. Retrieved from https://www.tensorflow.org/responsible_ai/privacy
- OECD (Organisation for Economic Co-operation and Development). (2023). Emerging Privacy Enhancing Technologies: Current Regulatory Landscape. OECD Digital Economy Papers. Retrieved from https://www.oecd.org/
- Bellavin, T., & Datta, A. (2022). The Privacy-Utility Trade-off in Synthetic Data Generation. Journal of Privacy and Confidentiality.
- Microsoft Research. (2024). SmartNoise: Differential Privacy for Everyone. Retrieved from https://opensource.microsoft.com/
- Information Commissioner’s Office (ICO – UK). (2022). PETs guidance: Synthetic data. Retrieved from https://ico.org.uk/
- Gartner. (2024). Market Guide for Synthetic Data. (Note: Referenced for industry trends; summary accessible via Gartner Insights).














