Software as a Service isn’t just another deployment model—it’s a wholesale reinvention of how software is built, sold, secured, and improved. In the past decade, SaaS has reshaped everything from pricing and product strategy to operations, security, and the speed of delivery. Today, growing cloud spend, widespread multi-cloud adoption, and API-driven ecosystems underscore how fast this shift is happening. In this guide, you’ll learn seven practical, high-impact ways SaaS is transforming the industry—and exactly how to implement each one, step by step.
Who this is for: founders, product leaders, engineers, RevOps and finance teams, security leaders, and CIOs who want a pragmatic, metrics-first roadmap to modernize software strategy without derailing day-to-day execution.
What you’ll walk away with: a tactical playbook for SaaS pricing and monetization, API-first and PLG execution, DevOps acceleration, AI feature integration, multi-tenant/multi-cloud architectures, and governance you can sell as a feature—not a tax.
Key takeaways
- SaaS replaces big-bang releases with continuous value delivery. Elite delivery performance correlates with faster deployments and quicker recovery—focus on the core four software delivery metrics to measure progress.
- Recurring and usage-based monetization aligns price with value. It also creates a foundation for product-led growth, lower acquisition friction, and better predictability.
- API-first design turns your product into a platform. Treat APIs like products with SLAs, versioning, and a developer experience that drives revenue, not just integration.
- Self-serve, PLG motions are now enterprise-grade. Large B2B purchases are increasingly processed through digital channels—instrument activation and paywalls with precision.
- AI becomes a native product capability. Rapid adoption means opportunities in copilots, automation, and insights—if you design guardrails and measure business outcomes, not just usage.
- Multi-tenant and multi-cloud architectures are the new reliability and cost levers. They reduce blast radius, improve economics, and meet data residency needs—when paired with strong FinOps and SRE practices.
- Trust is a feature. Security, compliance, auditability, and data governance have moved from box-checking to differentiators customers will pay for.
1) Continuous Delivery as the Default: Shipping Value Every Day
What it is & why it matters
SaaS breaks the cycle of infrequent, high-risk releases and replaces it with small, reversible changes shipped continuously. Teams that excel in deployment frequency, lead time for changes, change failure rate, and time to restore service deliver value faster and with fewer customer-facing incidents. Continuous delivery (CD) is now table stakes for competitive SaaS.
Requirements & low-cost alternatives
- Core requirements: source control with trunk-based workflows; automated CI/CD; cloud infrastructure with infrastructure-as-code; containerization; test automation; feature flags; robust observability (logs, traces, metrics).
- Low-cost alternatives: managed CI/CD services; lightweight container registries; open-source IaC; starter templates for pipelines and app scaffolding; usage of platform engineering blueprints.
Step-by-step implementation
- Baseline the four delivery metrics. Measure deployment frequency, lead time for changes, change failure rate, and time to restore.
- Adopt trunk-based development. Small PRs, mandatory automated checks, and feature flags to decouple deploy from release.
- Automate the path to production. One button (or commit) should build, test, scan, and deploy to a staging environment; then promote using approvals and progressive delivery.
- Introduce progressive delivery. Use canarying and gradual rollouts; control exposure with feature flags for instant rollback.
- Close the loop with SLOs. Define SLOs for latency, error rates, and availability; wire alerts to error budget policies that guide release velocity.
- Codify everything. Pipelines, infra, policies, and runbooks live in version control with change history.
Beginner modifications & progressions
- Start small: apply the pipeline to a single service; ship weekly → daily.
- Progression: add canary analysis and automated rollback, then adopt platform engineering patterns (golden paths, templates, paved roads).
Recommended cadence & KPIs
- Cadence: releases daily or on-demand; post-incident reviews within 48 hours.
- KPIs: deployment frequency, lead time, change failure rate, time to restore, error budget burn, and percent of releases gated by automated checks.
Safety, caveats & common mistakes
- Skipping test automation: slows you later. Aim for fast unit tests + pragmatic integration tests.
- Treating flags as forever: establish TTLs; regularly retire stale flags.
- No rollback plan: require fast rollback paths before exposing users.
Mini-plan (example)
- Today: baseline the four metrics; enable feature flags in one service.
- This week: ship via a managed CI/CD pipeline to staging and production with manual approval.
- Next week: adopt canary release for new features, add automated rollback, and set SLOs.
2) From Licenses to Recurring Value: Subscription & Usage-Based Monetization
What it is & why it matters
SaaS replaces perpetual licenses with recurring and/or metered revenue. This aligns price to realized value, lowers the barrier to entry, and supports self-serve motions. Longitudinal data shows subscription businesses have outpaced traditional models over the last decade+, highlighting the durability of recurring revenue.
Requirements & low-cost alternatives
- Core requirements: metering, billing, invoicing, collections/dunning, tax/VAT handling, revenue recognition, price/packaging experimentation, entitlement management, and analytics.
- Low-cost alternatives: start with tiered pricing + seat-based billing; bolt on simple usage meters (e.g., monthly credits) before granular per-event pricing.
Step-by-step implementation
- Choose a value metric. Seats, monthly active users, compute minutes, API calls, records processed, or outcomes (e.g., transactions).
- Design packaging. Good/Better/Best tiers with clear upgrade paths; attach usage overages to tiers to reduce bill shock.
- Implement metering and entitlements. Track usage at request or batch level; gate features reliably; expose real-time usage to customers.
- Close the loop with RevOps. Stand up dunning, failed-payment recovery, and revenue recognition; instrument price tests (A/B) and cohort analyses.
- Launch with transparent comms. Clear trial limits, “fair use” policies, and an annual option with savings to reduce churn.
Beginner modifications & progressions
- Start simple: seat-based plans + a single usage throttle (e.g., API calls).
- Progression: hybrid pricing (platform fee + usage), prepaid credits, and committed-use discounts; introduce plan-specific SLAs.
Recommended cadence & KPIs
- Cadence: pricing review quarterly; experimentation on a rolling basis.
- KPIs: MRR/ARR, ARPA, NRR/GRR, expansion vs. contraction MRR, free-to-paid conversion, payback period, LTV:CAC.
Safety, caveats & common mistakes
- Over-complex pricing: confuses buyers; limit the number of tiers and value metrics.
- Unpredictable bills: show real-time usage, alert at thresholds, and offer caps.
- Neglecting taxes/compliance: ensure correct tax calculation and invoicing by region; respect data residency requirements.
Mini-plan (example)
- Week 1: define the primary value metric; design three tiers.
- Week 2: instrument metering and entitlements; expose usage dashboards.
- Week 3: enable trials; add buy-in-product + annual prepay.
- Week 4: run a localized price test; track conversion and expansion.
3) API-First & Composable Platforms: Turning Products into Ecosystems
What it is & why it matters
SaaS thrives when products interoperate. API-first development treats APIs as the contract of your product, enabling integrations, partner ecosystems, and new revenue lines. Industry surveys show a large and rising share of teams identify as API-first, with notable improvements in API production speed and monetization.
Requirements & low-cost alternatives
- Core requirements: design-first workflows (OpenAPI/JSON Schema), an API gateway, authentication/authorization (OAuth, keys), rate limiting, versioning strategy, observability, and a developer portal with docs, SDKs, and examples.
- Low-cost alternatives: start with a single service gateway and autogen docs; offer a minimal portal (keys + examples) before scaling to a full marketplace.
Step-by-step implementation
- Design before build. Publish OpenAPI specs, run contract tests, and generate clients/servers.
- Standardize authentication and errors. Consistent error codes; provide sandbox keys and example payloads.
- Version with intent. Prefer additive changes; deprecate with long runway and clear migration guides.
- Invest in the developer experience. One-click API keys, copy-paste samples, and runnable recipes; measure time-to-first-call.
- Operationalize. Set per-plan rate limits; define availability and latency targets; monitor 4xx/5xx patterns.
- Monetize. Package API products, usage tiers, SLAs, and partner revenue-share programs; publish status pages and change logs.
Beginner modifications & progressions
- Start small: expose a single “golden” API with one great tutorial.
- Progression: offer event streaming/webhooks, a partner directory, and a certification program.
Recommended cadence & KPIs
- Cadence: spec reviews per release; status updates for incidents within one hour.
- KPIs: time-to-first-call, active apps/keys, API revenue, error rates/latency, partner retention, dependency health.
Safety, caveats & common mistakes
- Unstable contracts: breaking changes erode trust; treat APIs like public UIs.
- Weak auth/secrets hygiene: rotate keys, support least privilege, and discourage long-lived tokens.
- Noisy neighbors: enforce fair usage and tenant isolation at the gateway.
Mini-plan (example)
- Today: publish a clean OpenAPI spec for one critical capability.
- This week: launch a minimal developer portal with API keys and a runnable quickstart.
- Next week: add webhooks and per-plan rate limits; announce a partner beta.
4) Product-Led Growth (PLG): Enterprise-Grade Self-Serve
What it is & why it matters
SaaS has pushed enterprise buying toward self-serve trials, freemium tiers, and in-product conversions. A growing share of large B2B purchases now completes via digital self-serve channels. PLG reduces friction, expands top-of-funnel, and uses product usage to qualify and accelerate sales.
Requirements & low-cost alternatives
- Core requirements: event-level analytics, in-app onboarding, self-serve checkout, entitlement management, lifecycle messaging, and product usage scoring for sales.
- Low-cost alternatives: start with a single in-app checklist, basic trial limits, and a simple paywall backed by your billing system.
Step-by-step implementation
- Instrument activation. Define the “Aha” moment and the three actions most predictive of conversion.
- Design onboarding. Interactive checklists, templated sample data, and context-aware tips.
- Enable self-serve purchase. Trial → paid inside the app; instant plan upgrades; transparent annual discounts.
- Score leads from product usage. Create product-qualified lead (PQL) definitions and route to sales.
- Iterate pricing and UX. Test limits, upgrade prompts, and nudges; avoid dark patterns.
Beginner modifications & progressions
- Start with a free trial: time-bound with generous usage included.
- Progression: layered freemium (always-free core + paid power features), enterprise controls (SSO, audit logs), and assisted trials for high-stakes buyers.
Recommended cadence & KPIs
- Cadence: weekly growth experiments; monthly pricing review.
- KPIs: activation rate, time-to-value, free-to-paid conversion, expansion MRR, PQL→SQL conversion, NRR, payback period.
Safety, caveats & common mistakes
- One-size onboarding: segment by persona and job-to-be-done.
- Aggressive paywalls: upgrade prompts after value is demonstrated.
- Ignoring enterprise needs: ensure SSO, SCIM, audit logs, and data controls for procurement.
Mini-plan (example)
- Week 1: instrument activation events; define PQL criteria.
- Week 2: ship a 5-step in-app checklist and a clean trial paywall.
- Week 3: enable self-serve upgrades and usage notifications.
- Week 4: review cohort data; tune limits and prompts.
5) Data & AI Built In: From Features to Outcomes
What it is & why it matters
SaaS gives teams continuous access to real-world usage and outcome data. Combine this with modern AI, and you can build copilots, recommendations, anomaly detection, and automated workflows that materially improve customer outcomes. Surveys in 2024–2025 show rapid growth in regular use of generative AI across business functions, with software engineering among the top adopters.
Requirements & low-cost alternatives
- Core requirements: event pipelines, secure data lakes/warehouses, feature stores, model serving, guardrails (prompt safety, PII redaction), human-in-the-loop review, and offline evaluation harnesses.
- Low-cost alternatives: begin with hosted model APIs; restrict scope to well-bounded use cases; add retrieval and templates before training anything bespoke.
Step-by-step implementation
- Choose a narrow, high-value use case. Example: draft summarization, support deflection, assisted onboarding, or auto-classification.
- Design the control loop. Who approves outputs? What data powers prompts? What telemetry proves value?
- Ship a minimum viable assistant. Use a hosted model; redact sensitive data; log prompts/responses securely.
- Measure business outcomes. Time saved, ticket deflection, conversion lift, revenue per interaction, or quality scores.
- Harden and scale. Add content filters, evaluation datasets, offline tests, caching, and cost caps; explore fine-tuning only if ROI justifies it.
Beginner modifications & progressions
- Start with human-in-the-loop: require confirmation before actions are executed.
- Progression: event-driven automations, multi-agent orchestration, and domain-specific fine-tunes once data governance matures.
Recommended cadence & KPIs
- Cadence: weekly model-quality reviews; monthly security audits of prompts and logs.
- KPIs: task completion rate, time saved, cost per assisted task, precision/recall for classifiers, user satisfaction, and deflection rates.
Safety, caveats & common mistakes
- Data leakage & privacy: redact sensitive info, minimize retention, and isolate customer data per tenant.
- Unmeasured hallucinations: score quality with golden datasets; block risky actions without human approval.
- Model sprawl: standardize on approved providers, a routing layer, and cost governance.
Mini-plan (example)
- This week: ship a support-reply assistant with human approval.
- Next week: add retrieval from approved knowledge bases; evaluate on a labeled set.
- After 30 days: expand to auto-tagging and summarize usage gains in a business review.
6) Multi-Tenant, Multi-Cloud: Reliability and Economics at Scale
What it is & why it matters
SaaS economics depend on isolating tenants while pooling infrastructure to lower cost and improve reliability. Meanwhile, a large majority of organizations operate in multi-cloud and hybrid models. This combination—purposeful tenancy models plus deliberate multi-cloud—helps balance performance, compliance, and cost.
Requirements & low-cost alternatives
- Core requirements: tenancy model (pooled, siloed, or hybrid), VPC/VNet isolation, automated provisioning, per-tenant quotas and telemetry, cross-region replication, disaster recovery, and cost allocation by tenant.
- Low-cost alternatives: begin with a pooled model and a “silo” option for regulated customers; use managed database instances with schema-per-tenant before moving to cluster partitioning.
Step-by-step implementation
- Choose a tenancy strategy. Pooled for efficiency; siloed for high-end contracts; hybrid when you need both.
- Define a region and residency plan. Map customer segments to regions and document data movement.
- Automate provisioning and guardrails. Self-service tenant creation; quotas and rate limits per plan; per-tenant encryption keys where needed.
- Engineer for failure. Cross-AZ by default; active-passive across regions; run chaos drills; document RTO/RPO.
- Adopt FinOps. Tag spend by tenant and environment; publish cost per active customer; drive unit-economics improvements via caching and storage lifecycle policies.
Beginner modifications & progressions
- Start pooled: one cluster with strong logical isolation; add per-tenant throttles.
- Progression: dedicated compute or storage for high-SLA customers; cross-cloud failover for mission-critical verticals.
Recommended cadence & KPIs
- Cadence: monthly resilience tests; quarterly cost optimization reviews.
- KPIs: availability and SLO attainment, cost per tenant, gross margin, performance P95/P99, and percentage of workloads covered by DR exercises.
Safety, caveats & common mistakes
- Noisy neighbors: enforce per-tenant limits and prioritize critical tenants.
- Unclear residency story: document where data lives and how it’s replicated.
- Skipping game days: reliability emerges from practice, not policy docs.
Mini-plan (example)
- Week 1: define tenancy model and quotas; tag resources for cost showback.
- Week 2: enable cross-AZ redundancy and backups with verified restores.
- Week 3: run a failover test; publish outcomes to stakeholders.
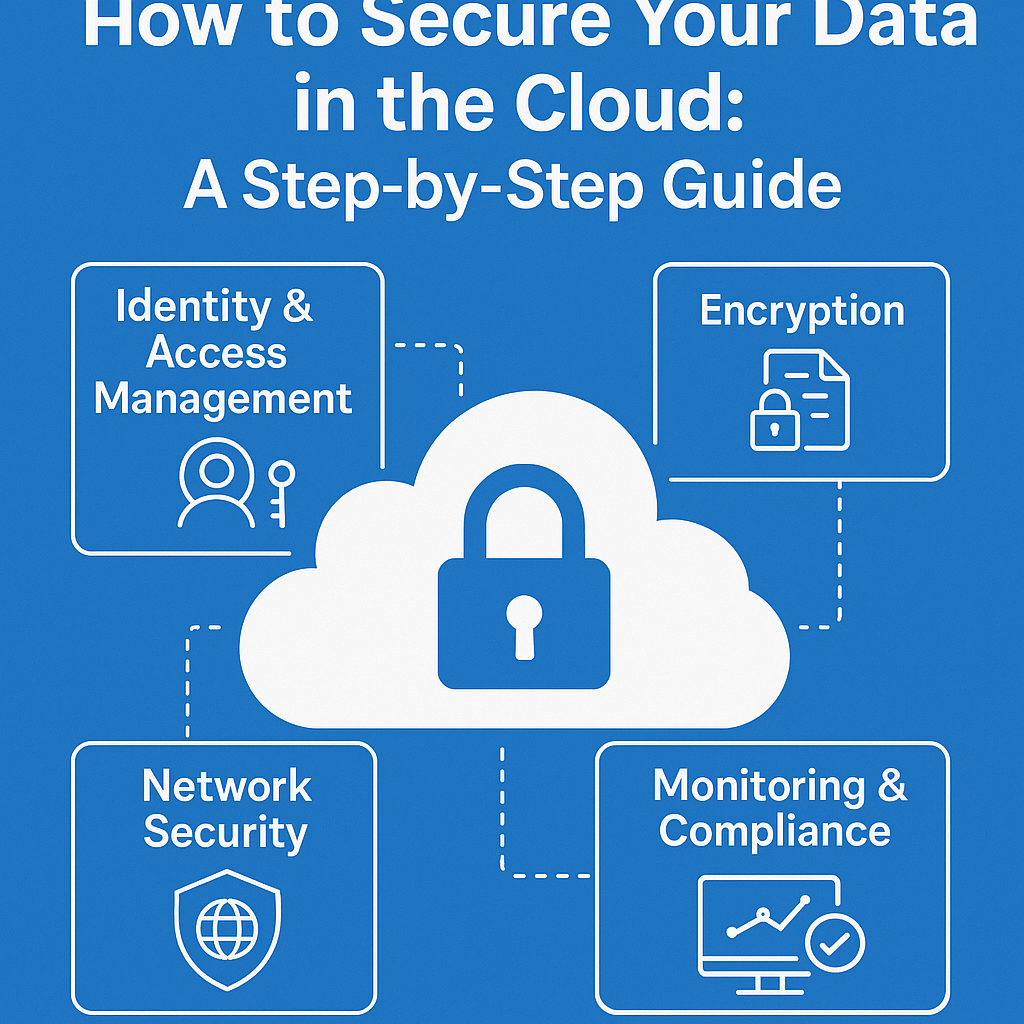
7) Governance, Security & Compliance as Features (Not Tax)
What it is & why it matters
Customers now evaluate trust like any other feature. They expect secure defaults, auditable actions, data controls, and clear uptime/incident practices. Strong governance reduces sales friction, accelerates procurement, and unlocks larger contracts.
Requirements & low-cost alternatives
- Core requirements: secure SDLC (code scanning, dependency hygiene, container scanning), secrets management, least-privilege IAM, tenant-scoped encryption, audit logs, role-based access, data retention/deletion, incident response, and periodic third-party assessments.
- Low-cost alternatives: start with managed secret stores, automated dependency updates, and a centralized access review cadence; provide export and deletion APIs early.
Step-by-step implementation
- Shift left. Automatic code and container scanning in CI; minimum test/security gates before deploy.
- Harden identity and data. SSO, MFA, SCIM, least-privilege roles, per-tenant keys when feasible; encryption in transit and at rest everywhere.
- Make it auditable. Immutable audit logs, admin action trails, and customer-visible logs for critical events.
- Operational readiness. Document incident response, define severities and SLAs, and practice tabletop exercises.
- Compliance automation. Map controls to policies; keep a live asset inventory; maintain change records; provide customers with up-to-date security documentation and status pages.
Beginner modifications & progressions
- Start with essentials: SSO, MFA, audit logging, DPA templates, and a public status page.
- Progression: BYOK, regional data controls, advanced customer log streaming, and attestation packages tailored to regulated buyers.
Recommended cadence & KPIs
- Cadence: quarterly access reviews; monthly vulnerability SLAs; incident postmortems within 5 days.
- KPIs: mean time to detect/respond, patch SLAs met, percent of services with threat models, coverage of security tests, and successful access review rate.
Safety, caveats & common mistakes
- Security theater: policies without enforcement or monitoring.
- Opaque posture: hiding incidents erodes trust; publish timely updates and post-incident learnings.
- Over-collecting data: minimize and segregate; document retention and deletion clearly.
Mini-plan (example)
- Today: enable SSO/MFA and immutable audit logs for all admin actions.
- This week: centralize secrets and rotate high-risk credentials; publish your incident severity matrix.
- Next week: ship customer-visible security docs and data export/deletion endpoints.
Quick-Start Checklist (print this)
- Pick one product area to pilot continuous delivery (baseline the four delivery metrics).
- Choose a simple, aligned value metric (e.g., seats + a light usage meter).
- Publish one “golden path” API with spec, keys, and a runnable quickstart.
- Add a 14–30 day trial with in-app checkout and a five-step onboarding checklist.
- Ship one safe, high-ROI AI feature behind human approval.
- Document your tenancy model and quotas; verify backups and one cross-AZ failover.
- Turn on SSO/MFA, centralize secrets, and publish a status page plus DPA templates.
Troubleshooting & Common Pitfalls
- Releases still feel risky. Your change sets are too large or your tests are too slow. Shrink PRs, parallelize tests, and deploy behind feature flags with canaries.
- Trials don’t convert. You haven’t defined activation. Instrument the “Aha” moment and ensure onboarding hits it within the first session.
- Runaway cloud costs. No ownership or showback. Tag by service/tenant, set budgets and alerts, and track cost per active customer monthly.
- APIs are under-used. Developer experience is weak. Improve docs, samples, and keys issuance; measure time-to-first-call and error rates.
- AI feature backfires. You shipped output without guardrails. Add approval steps, redaction, and offline evaluation; measure outcome metrics, not just usage.
- Security slows deals. Package trust as a product: SSO, audit logs, data controls, and live status/uptime are part of your enterprise SKUs.
How to Measure Progress (build a one-page scorecard)
Delivery & Reliability
- Deployment frequency, lead time for changes, change failure rate, time to restore, SLO attainment, error budget burn.
Growth & Monetization
- Activation rate, free-to-paid conversion, PQL→SQL conversion, NRR/GRR, ARPA, payback period, churn.
Platform & Ecosystem
- Time-to-first-call, active API keys/apps, partner revenue, API error rates/latency.
AI & Outcomes
- Task completion rate, time saved, deflection, model quality (precision/recall), cost per assisted task.
Trust & Economics
- Uptime, incident count and MTTR, patch SLAs met, cost per tenant, gross margin, access review completion.
A Simple 4-Week Starter Plan
Week 1 – Baseline & Blueprint
- Measure the four delivery metrics; define SLOs for one service.
- Choose a value metric and sketch three pricing tiers.
- Pick one API and write an OpenAPI spec; stub endpoints.
- Draft a 5-step onboarding checklist tied to your activation events.
- Security quick wins: enable SSO/MFA, centralize secrets, and publish a status page.
Week 2 – Ship the Foundation
- Stand up CI/CD to staging and production; adopt feature flags.
- Implement metering and entitlements for your chosen value metric.
- Launch a minimal developer portal (keys + runnable quickstart).
- Enable a time-boxed trial with transparent limits and in-app checkout.
- Document tenancy model and quotas; verify automated backups and restore.
Week 3 – Prove Value
- Turn on progressive delivery (canary) for one feature; add automated rollback.
- Release the trial + onboarding checklist; instrument activation and time-to-value.
- Ship one AI-assisted workflow with human-in-the-loop approval.
- Tag cloud resources for cost showback; publish cost per active customer.
Week 4 – Optimize & Tell the Story
- Review delivery metrics and postmortems; retire stale flags.
- Tune pricing/limits based on trial cohorts; run one A/B on upgrade prompts.
- Add webhooks and per-plan rate limits to your API.
- Run a failover drill; publish a short resilience report to stakeholders.
- Create a one-page scorecard and schedule a monthly business review.
FAQs
- Is SaaS always cheaper than on-prem?
Not always. It’s cheaper to start, but cost discipline matters at scale. Track cost per active customer, right-size resources, and optimize storage lifecycle to prevent surprise bills. - How do I pick the right value metric for pricing?
Choose a metric customers understand that maps to value you create and that you can meter precisely (seats, transactions, records, compute minutes). Pilot with a small segment before rolling out. - Can PLG work in enterprise markets?
Yes. Buyers increasingly prefer digital self-serve for evaluation and even purchasing. Pair PLG with enterprise features (SSO, audit logs, data controls) and a sales-assist motion. - What’s the minimum I need for an API program?
A stable spec, consistent auth, good docs, a sandbox, and clear limits/SLAs. Measure time-to-first-call and error rates; fix developer experience before scaling. - Where should I start with AI features?
Pick a small, high-ROI workflow (e.g., summarization, classification). Add human approval, redaction, and offline evaluation. Prove time saved or quality lift before expanding. - Do I need multi-cloud from day one?
No. Start with strong multi-AZ resilience. Add cross-region and then multi-cloud only for clear requirements (compliance, vendor risk, large enterprise SLAs). - How do I prevent vendor lock-in?
Abstract with open standards (containers, IaC, OpenAPI), design clean interfaces, and keep data export paths. Multi-cloud helps, but portability practices matter more. - What if my trial users don’t convert?
Revisit activation: are users reaching value in the first session? Improve onboarding, sample data, and templates. Add usage notifications and contextual upgrade prompts. - How transparent should I be about incidents?
Very. Publish status updates promptly, share post-incident learnings, and explain remediation. Transparency builds trust and shortens procurement cycles. - What security basics must every SaaS include?
SSO/MFA, least-privilege IAM, encrypted data in transit/at rest, immutable audit logs, secrets management, vulnerability and dependency scanning, and documented incident response. - How often should I change pricing?
Review quarterly, but ship carefully. Pilot changes with cohorts, communicate clearly, and provide grandfathering or credit where appropriate. - What are the most important delivery metrics to track?
Deployment frequency, lead time for changes, change failure rate, and time to restore service—tie them to SLOs and your error budget policies.
Conclusion
SaaS has matured from “software in a browser” to a complete operating model for building, selling, and safeguarding digital products. Continuous delivery shortens the distance between ideas and impact. Recurring and usage-based monetization aligns incentives. API-first design and PLG expand reach and revenue. AI turns data into outcomes. Multi-tenant, multi-cloud architectures and governance-as-features deliver the reliability and trust that win enterprise deals.
Pick one or two plays from this guide and ship them this month. Measure relentlessly, tell the story with your scorecard, and keep iterating—the SaaS advantage compounds.
CTA: Start your 4-week plan today: pick one service, one value metric, and one API—and ship your first improvements this week.
References
- Cloud computing trends: 2024 State of the Cloud Report, Flexera, March 28, 2024. https://www.flexera.com/blog/finops/cloud-computing-trends-flexera-2024-state-of-the-cloud-report/
- Flexera 2024 State of the Cloud: Managing Spending Is Top Challenge (press release), Flexera, March 12, 2024. https://www.flexera.com/about-us/press-center/flexera-2024-state-of-the-cloud-managing-spending-top-challenge
- 2024 State of the Cloud Report (PDF), Flexera, 2024. https://sc102-prod-cd.azurewebsites.net/-/media/files/noram/free/state-of-the-cloud-report-2024.pdf
- Global cloud spend to surpass $700B in 2025 as hybrid models rise, CIO Dive (reporting on analyst forecast), November 19, 2024. https://www.ciodive.com/news/cloud-spend-growth-forecast-2025-gartner/733401/
- Subscription Economy Index: Flexible, Recurring Monetization Models Drive 3.4x Faster Growth than the S&P 500 Over the Past 12 Years, Zuora (press release), April 9, 2024. https://www.zuora.com/press-release/sei-report-2024/
- 2024 State of the API Report (overview), Postman, 2024. https://www.postman.com/state-of-api/2024/
- 2024 State of the API Report (PDF), Postman, October 2024. https://voyager.postman.com/doc/postman-state-of-the-api-report-2024.pdf
- 2024 Accelerate State of DevOps Report (overview), DORA/Google Cloud, October 22, 2024. https://cloud.google.com/devops/state-of-devops
- 2024 Accelerate State of DevOps Report (PDF), DORA/Google Cloud, 2024. https://services.google.com/fh/files/misc/2024_final_dora_report.pdf
- Forrester’s B2B Marketing & Sales Predictions 2025: More Than Half Of Large B2B Purchases Will Be Processed Through Digital Self-Serve Channels, Forrester (press release), October 22, 2024. https://investor.forrester.com/news-releases/news-release-details/forresters-b2b-marketing-sales-predictions-2025-more-half-large
- The state of AI in early 2024: Gen AI adoption spikes and starts to generate value, McKinsey (article), May 30, 2024. https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai-2024
- The state of AI: How organizations are rewiring to capture value (PDF), McKinsey, March 5, 2025. https://www.mckinsey.com/~/media/mckinsey/business%20functions/quantumblack/our%20insights/the%20state%20of%20ai/2025/the-state-of-ai-how-organizations-are-rewiring-to-capture-value_final.pdf