
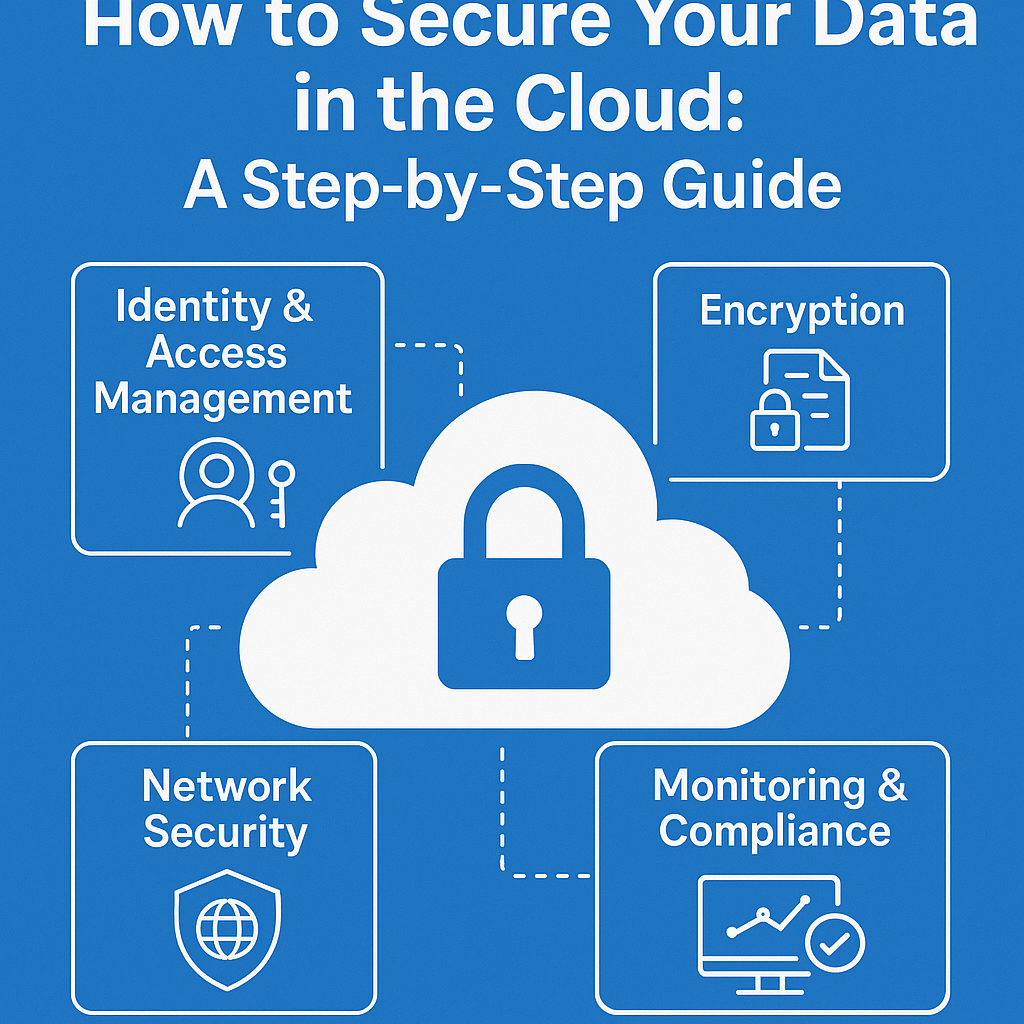
Open source is the backbone of modern software—from cloud platforms and AI stacks to the smallest embedded devices. That ubiquity brings a profound security paradox. On one hand, open code and community review can raise the bar for transparency, resilience, and rapid response. On the other, sprawling dependencies, uneven maintenance, and rushed adoption can quietly expand the attack surface. This comprehensive analysis examines how open source reshapes cybersecurity—its benefits, risks, and the concrete practices that turn transparency into trust. You’ll learn how to select healthier dependencies, generate and use SBOMs, harden your build and release pipelines, prove provenance, sign and verify artifacts, adopt memory-safe code, operationalize vulnerability management, and respond to incidents faster with less chaos. It’s written for engineering leaders, security architects, DevOps/SRE teams, and founders who want a practical roadmap, not platitudes.
Key takeaways
- Open source is everywhere—and so are its risks. Most production codebases contain open source, and a large share ship with known vulnerabilities and outdated components.
- Transparency is only an advantage if you operationalize it. SBOMs, provenance, signatures, and reproducible builds convert visibility into verifiable trust.
- Healthy dependency choices pay compounding security dividends. Simple checks on maintenance, responsiveness, and release hygiene drastically reduce future firefighting.
- Automate everything you can. Continuous scanning, update automation, and policy gates shrink mean time to remediate and keep drift at bay.
- Memory safety and rigorous testing matter. Shifting new critical code to memory-safe languages and adding fuzzing/sandboxing cut entire classes of exploits.
- Security is a team sport. Consuming, contributing, and responding to issues in open source require clear policies, SLAs, and respectful upstream collaboration.
Disclaimer: This article provides general security guidance and is not legal advice. For regulatory, contractual, or liability questions, consult qualified legal counsel and a security professional familiar with your industry.
1) Establish an open-source security strategy and policy
What it is & core benefits
A concise, enforceable policy that defines how your organization selects, tracks, updates, and contributes to open-source components. Done well, it aligns engineering, security, procurement, and legal so that shipping product doesn’t mean inheriting unknown risk.
Benefits: clearer decision rights, faster audits, easier incident response, predictable SLAs for patching, and less rework during compliance reviews.
Requirements / prerequisites
- A named owner (often a security or platform lead) and an internal review group that can make fast calls.
- A repository for policy documents and checklists (in your docs portal or monorepo).
- Simple intake forms for new dependencies and a templated exception process (because reality happens).
- Low-cost alternative: start with a one-page policy and a shared spreadsheet while you pilot.
Step-by-step (starter draft)
- Define scope & roles. Who approves new dependencies, who runs SBOMs, who triages vulns, who talks to upstream?
- Set acceptance criteria. Minimum maintenance signals, license compatibility, critical bug response time, release cadence expectations.
- Pick tooling. Choose an SCA scanner, SBOM format(s), update automation, and CI gates.
- Write patching SLAs. E.g., critical within 48–72 hours, high within 7 days, medium within 30 days, low by next quarterly cycle.
- Create an exception path. Document risk acceptance and a back-out date.
- Publish & train. Keep it in your engineering handbook; review in onboarding.
Beginner modifications & progressions
- Start simple: policy + spreadsheet + one SCA tool.
- Progress: enforce in CI with policy-as-code, hook procurement for commercial support where needed, and add quarterly scorecards for product teams.
Recommended frequency / metrics
- Quarterly policy review.
- KPIs: % deps meeting policy, median days-to-update, % repos with enforced CI policy gates, # exceptions open >30 days.
Safety, caveats, common mistakes
- Avoid “policy theater.” If a rule isn’t enforceable in CI, expect drift.
- Don’t block releases without offering remediation paths.
- Keep the exception path tight or it becomes the default.
Mini-plan (2–3 steps)
- Publish a one-page policy with patch SLAs.
- Enable SBOM generation in CI for one flagship service.
- Turn on update automation and measure time-to-merge.
2) Inventory your code with SBOMs (and use them)
What it is & core benefits
A Software Bill of Materials (SBOM) enumerates the packages, versions, and licenses in your software. SBOMs are the foundation for continuous visibility, faster vulnerability triage, license compliance, and incident response. Widely used formats include SPDX and CycloneDX—both interoperable, tool-friendly, and designed for machine consumption.
Benefits: instant component discovery, targeted patching, fewer surprises during audits and M&A, and easier customer security reviews.
Requirements / prerequisites
- CI access to build artifacts.
- An SCA scanner or SBOM generator that supports SPDX/CycloneDX.
- Low-cost: many open-source tools generate SBOMs; start with JSON output stored alongside artifacts.
Step-by-step
- Generate SBOMs in CI for every build, not just releases.
- Attach SBOMs to artifacts in your registry and release pages.
- Store SBOMs centrally with searchable metadata (service, version, release date).
- Continuously enrich with known vulnerabilities and license flags.
- Expose SBOMs to responders and customer-facing teams via a simple portal or link.
Beginner modifications & progressions
- Beginner: nightly job that scans main branch and publishes SBOMs.
- Advanced: SBOMs for dev, staging, prod; vendor SBOM ingestion; VEX (vulnerability exploitability exchange) to annotate “not affected.”
Recommended frequency / metrics
- Generate every build.
- KPIs: SBOM coverage (% builds with SBOM), SBOM freshness (days since generated), % vulns with VEX disposition.
Safety & common mistakes
- Don’t treat SBOMs as static PDFs. They must be queried, diffed, and kept current.
- Avoid mismatched formats—standardize early.
Mini-plan
- Enable SPDX or CycloneDX export in CI.
- Upload SBOMs to your artifact registry automatically.
- Add a dashboard that lists top vulnerable components by service.
3) Choose healthier dependencies with simple, objective signals
What it is & core benefits
A dependency health check is a lightweight gate before adoption. You assess whether a project is well maintained, responsive to security issues, and safe to integrate.
Benefits: fewer abandonware surprises, faster patches, easier vendor/security reviews, and smoother upgrades.
Requirements / prerequisites
- A short checklist (copy into your repo templates).
- Optional: integrate an automated security scorecard tool to collect signals from repos.
Step-by-step
- Check release cadence (e.g., ≥1 release/6 months for critical deps).
- Review issue/PR responsiveness (median time to first response).
- Confirm security hygiene (responsible disclosure process, signed tags, CI checks).
- Verify license compatibility and dual-license gotchas.
- Record the assessment and decision in your dependency intake form.
Beginner modifications & progressions
- Beginner: manual checklist for top 10 new deps.
- Progress: automate checks with scorecard tools and enforce minimum thresholds in CI.
Recommended frequency / metrics
- Run at adoption and quarterly for critical deps.
- KPIs: % critical deps with recent releases, median maintainer response time, % deps meeting minimum score thresholds.
Safety & mistakes
- Don’t let “star counts” sway decisions. Evaluate maintainer behavior, not popularity.
- Avoid hard pinning to forks unless you commit to long-term maintenance.
Mini-plan
- Add a DEPENDENCIES.md template with 5 must-check items.
- Automate score collection for GitHub repos.
- Block merges when critical deps fail baseline checks.
4) Operationalize vulnerability management for open source
What it is & core benefits
A repeatable process and tooling to detect, triage, remediate, and verify vulnerabilities in third-party components—without drowning teams in noise. Expect spikes when major issues surface; the process should absorb them.
Benefits: lower mean time to remediate (MTTR), fewer emergency hotfixes, less dependency drift, and cleaner audits.
Requirements / prerequisites
- SCA scanning wired into CI and scheduled scans of production images.
- Clear SLAs by severity.
- Ticket automation to route findings to owning teams.
Step-by-step
- Scan every build and nightly in production registries.
- Deduplicate by package+version and suppress false positives with documented justifications.
- Prioritize by reachable/exploitable path, service criticality, and exposure.
- Patch via update automation (next section) or temporary mitigations.
- Verify with regression tests and deploy with canary/gradual rollout.
- Review weekly to close old tickets and nudge exceptions.
Beginner modifications & progressions
- Beginner: weekly CSV export + manual triage.
- Progress: policy-as-code gates, exploitability analysis, and VEX to mark “not affected.”
Recommended frequency / metrics
- Every build and nightly.
- KPIs: MTTR by severity, % critical vulns open >7 days, % repos failing CI gates, # false positives suppressed with justification.
Safety & mistakes
- Avoid alert fatigue: tune scanners; ban duplicate tickets across services.
- Don’t auto-close without deploy verification.
Mini-plan
- Enable CI scanning for top 5 services.
- Add a weekly security triage stand-up (30 minutes).
- Publish a public-facing status field: “patch available”, “patch applied”, “deployed”.
5) Shrink patch windows with update automation
What it is & core benefits
Update bots monitor dependencies, open pull requests to bump versions, and link changelogs. Combined with tests, they turn patching into a background task.
Benefits: shorter exposure windows, fewer manual chores, and a predictable cadence for change.
Requirements / prerequisites
- CI tests with decent coverage; container/image rebuilds for infra.
- An update bot (e.g., Renovate or Dependabot).
- A merge policy (automerge for low-risk patches after tests pass).
Step-by-step
- Turn on update automation for application and base image dependencies.
- Group low-risk patches (e.g., dev dependencies) to reduce PR noise.
- Configure branch protection and automerge rules.
- Rotate staging frequently; use canaries in production.
Beginner modifications & progressions
- Beginner: weekly PR batches.
- Progress: daily small PRs with automerge + rollback playbooks.
Recommended frequency / metrics
- Daily checks; merges as tests pass.
- KPIs: median days-to-update, PR backlog size, % automerged with zero incidents.
Safety & mistakes
- Don’t automerge major version bumps without explicit review.
- Keep a fast rollback path; update bots can be noisy during ecosystem breaks.
Mini-plan
- Enable bot for three critical services.
- Automerge patch/minor bumps after tests pass.
- Canary deploy and monitor error budgets.
6) Prove provenance with supply-chain attestations
What it is & core benefits
Provenance describes how a build was produced—by which builder, from which source, with what steps and inputs. Supply-chain frameworks define levels of assurance and standardized attestations for provenance.
Benefits: makes tampering harder, enables downstream verification, and lets customers trust that artifacts came from your pipeline.
Requirements / prerequisites
- A CI/CD system capable of generating provenance attestations.
- Storage for attestations and a way to link them to artifacts.
- Optional: standardized formats (e.g., in-toto predicates) for compatibility.
Step-by-step
- Instrument builds to emit provenance: source URL, commit, builder identity, steps, and inputs.
- Attach attestations to artifacts in your registry.
- Gate deployments on verifying provenance for required levels.
- Expose a simple verification command to customers and internal teams.
Beginner modifications & progressions
- Beginner: provenance for release builds only.
- Progress: provenance for every build; enforce verification in deploy jobs.
Recommended frequency / metrics
- Every build.
- KPIs: % artifacts with valid provenance, % deployments blocked for missing or invalid attestations.
Safety & mistakes
- Don’t let untrusted runners produce “trusted” artifacts.
- Align source control permissions with build trust—no sense in proving provenance if any maintainer can bypass review.
Mini-plan
- Emit in-toto provenance for one service.
- Store attestations next to images.
- Add a deployment step that verifies provenance before rollout.
7) Sign and verify everything (releases, images, SBOMs)
What it is & core benefits
Signature frameworks allow developers to sign release files, container images, and SBOMs with minimal key management, recording each signing event in a public, tamper-resistant log. Consumers verify signatures before trusting an artifact.
Benefits: protects against substitution attacks, confirms author identity, provides a forensic trail, and increases customer trust.
Requirements / prerequisites
- Access to your container/image registry and release distribution channel.
- A signing toolchain that supports keyless flows via identity providers.
- Policies in CI/CD to verify signatures before use.
Step-by-step
- Sign release artifacts, images, and SBOMs during CI.
- Publish signatures and store them with the artifact.
- Verify signatures in downstream build stages and at deploy time.
- Rotate identities and monitor the signing transparency log.
Beginner modifications & progressions
- Beginner: sign images only.
- Progress: sign all artifacts (including SBOMs) and enforce verification in the cluster admission controller.
Recommended frequency / metrics
- Every artifact, every release.
- KPIs: % artifacts signed, % deployments blocked due to invalid or missing signatures, time to detect signature anomalies.
Safety & mistakes
- Avoid shadow pipelines that push unsigned artifacts to production.
- Make verification failures fail closed with clear errors, not warnings.
Mini-plan
- Sign your container images in CI.
- Configure verification in staging.
- Promote to production after a week of clean signal.
8) Make builds reproducible (and verifiable)
What it is & core benefits
Reproducible builds ensure the same source and environment always produce the same binary. A third party can rebuild and confirm byte-for-byte identity, proving the binary came from the published source.
Benefits: detects hidden tampering, strengthens the chain of custody, and reinforces customer trust.
Requirements / prerequisites
- Deterministic build settings (sorted inputs, fixed timestamps, pinned toolchains).
- Build environment capture (containerized builds) and a rebuilder or verifier.
Step-by-step
- Containerize your build environment; pin compilers and dependencies.
- Eliminate nondeterminism (timestamps, random seeds).
- Compare hashes of independent rebuilds; publish results.
- Integrate a rebuild verifier in release pipelines.
Beginner modifications & progressions
- Beginner: make one library reproducible as a pilot.
- Progress: extend across languages; publish public reproducibility dashboards.
Recommended frequency / metrics
- Every release.
- KPIs: % artifacts reproducible, time to detect divergence, # of nondeterminism sources eliminated.
Safety & mistakes
- Be realistic: full reproducibility across polyglot repos takes time. Start with critical artifacts.
- Document rebuild instructions as part of your release notes.
Mini-plan
- Dockerize your build for one service.
- Remove timestamp nondeterminism.
- Verify that two builds from the same commit match exactly.
9) Reduce whole classes of exploits with memory-safe code and sandboxing
What it is & core benefits
Memory safety bugs (e.g., use-after-free, buffer overflows) have historically powered a large fraction of severe vulnerabilities. Shifting new system-level code to memory-safe languages, adding sandboxing, and hardening legacy code can shrink that attack surface dramatically.
Benefits: fewer critical bugs, smaller patch fire drills, safer integration of complex native libraries.
Requirements / prerequisites
- Agreement on language choices for new components.
- A triage of legacy native code and feasible wrappers/sandboxes.
- Training for teams adopting a new language and FFI boundaries.
Step-by-step
- Adopt a memory-safe language for new native components.
- Wrap legacy code behind safer interfaces; apply compiler hardening and sanitizers.
- Sandbox high-risk components with strict privileges and seccomp/AppArmor equivalents.
- Track metrics: memory-corruption bug counts, exploitability, and time-to-fix.
Beginner modifications & progressions
- Beginner: designate one “safety critical” area for memory-safe rewrites.
- Progress: make memory-safe the default for new components; plan gradual rewrites for hot paths.
Recommended frequency / metrics
- Quarterly reviews of memory-related vulnerabilities; track percentage of new code written in safe languages.
- KPIs: % of new code in safe languages, # of memory-safety bugs year-over-year, % covered by sanitizers.
Safety & mistakes
- Don’t “big-bang” rewrite everything. Target risk hot spots first.
- Beware FFI edges; enforce strict audits where safe and unsafe code meet.
Mini-plan
- Pick one service with recurring memory bugs.
- Rewrite the parsing layer in a memory-safe language.
- Sandbox the legacy remainder until the next milestone.
10) Add fuzzing, property tests, and negative testing to dependencies and your code
What it is & core benefits
Fuzzing feeds randomized, malformed inputs to uncover crashes and logic flaws. Combined with property-based tests and negative tests, it exposes edge cases that traditional unit tests miss—especially in parser-heavy libraries and cryptographic code.
Benefits: finds serious bugs early, prevents regression, and boosts confidence when upgrading third-party libraries.
Requirements / prerequisites
- Language-appropriate fuzzers and harnesses.
- CI time budget and crash triage workflow.
- For dependencies without harnesses, simple adapters to exercise their APIs.
Step-by-step
- Identify high-risk surfaces (parsers, deserializers, crypto, network).
- Write fuzz harnesses and run locally to shake out crashes.
- Run in CI with time-boxed jobs; more intensive jobs run nightly.
- Upstream fixes for discovered issues where practical.
Beginner modifications & progressions
- Beginner: fuzz one critical dependency.
- Progress: continuous fuzzing across repos, crash deduplication, and coverage tracking.
Recommended frequency / metrics
- Per-commit smoke + nightly deep fuzz runs.
- KPIs: crashes found/fixed, code coverage, time-to-fix fuzz-found bugs.
Safety & mistakes
- Fuzzing is compute-hungry; time-box it to avoid CI gridlock.
- Reproducibility matters—store minimized corpora for regressions.
Mini-plan
- Add a fuzzer to your JSON parser.
- Run 10-minute fuzz jobs on PRs.
- Nightly, run 2-hour jobs and email a digest to owners.
11) Prepare for incidents with SBOM-driven response
What it is & core benefits
When a high-impact flaw lands in the news, minutes matter. An SBOM-driven playbook helps you answer “Where do we use this?” immediately, prioritize the riskiest locations, and publish credible status updates to customers.
Benefits: faster triage, fewer chaotic meetings, less customer churn, better regulator and stakeholder confidence.
Requirements / prerequisites
- Central SBOM index with service ownership metadata.
- A lightweight command or dashboard to search for components by name/version.
- Pre-agreed internal and customer status templates.
Step-by-step
- Search SBOMs for affected versions.
- Rank exposure (internet-facing? privileged? processing untrusted input?).
- Patch or mitigate, starting with high-exposure services.
- Communicate: publish “detect, patch, deploy” status as you progress.
- Post-incident review to improve coverage and SLAs.
Beginner modifications & progressions
- Beginner: manual SBOM search; spreadsheet of affected services.
- Progress: scripted queries with auto-generated tickets and dashboards.
Recommended frequency / metrics
- On demand; rehearse quarterly.
- KPIs: time to inventory impact, time to patch, time to deploy to 90% of fleet.
Safety & mistakes
- Don’t overload a single team; incident response is cross-functional.
- Avoid “we think we’re safe” messaging—publish clear, version-specific statements.
Mini-plan
- Create a runbook: “search → prioritize → patch → verify → communicate.”
- Drill it with a recent CVE in a staging-only exercise.
- Record times and fix bottlenecks.
12) Contribute back safely and responsibly
What it is & core benefits
Contributing fixes upstream isn’t altruism—it’s supply-chain risk management. Your patches reduce the delta you must carry, speed your own updates, and improve security for everyone.
Benefits: fewer long-lived forks, better relationships with maintainers, faster fixes in future releases.
Requirements / prerequisites
- Internal guidelines for contributions (naming, email, code of conduct).
- Legal green-light for contribution agreements when required.
- A simple internal review for security-sensitive changes.
Step-by-step
- Nominate maintainers for key dependencies and allocate time for upstream work.
- Contribute fixes with clear reproduction cases and tests.
- Backport or vendor only when necessary; upstream first whenever possible.
- Track upstream issue/PR status and mirror in your backlog.
Beginner modifications & progressions
- Beginner: fix docs and small bugs to build trust.
- Progress: co-maintain critical components you rely on heavily.
Recommended frequency / metrics
- Quarterly review of contribution impact.
- KPIs: # upstreamed fixes, # forks maintained internally, time from local patch → upstream release.
Safety & mistakes
- Don’t surprise maintainers with giant diffs; collaborate early.
- Follow project security disclosure processes for sensitive bugs.
Mini-plan
- Identify top 5 critical dependencies.
- File two small PRs per quarter to each, starting with test or doc improvements.
- Track merged PRs and release uptake.
Quick-start checklist
- One-page open-source policy with patch SLAs and an exception path
- SBOM generation (SPDX or CycloneDX) enabled in CI for at least one service
- Update automation turned on; automerge patch/minor with tests
- Provenance attestation generated and stored with artifacts
- Image and release signing; verification enforced in staging
- Pilot reproducible builds for one artifact
- Memory-safe language adopted for one new component
- Basic fuzzing harness on a high-risk parser
- SBOM-driven incident response drill completed this quarter
Troubleshooting & common pitfalls
- “Our scanner shows thousands of findings.”
Start with top services and high-impact packages. Deduplicate by package+version and use exploitability signals. Apply VEX where you can prove non-reachability. - “Update bots create PR floods.”
Group dev dependency updates. Set schedules (e.g., mornings) and automerge only for patch/minor. Gate major versions behind explicit approval. - “Upstream is slow to respond.”
Provide a minimal reproduction and proposed fix. If you must fork, set a sunset date and plan to return to upstream. - “Provenance verification is blocking deploys unexpectedly.”
Verify that all builders use the same identity controls. Ensure cache layers aren’t injecting unsigned artifacts. - “Reproducible builds keep failing.”
Pin the toolchain; scrub timestamps; use deterministic archives. Diff build graphs to find nondeterministic steps. - “We can’t rewrite legacy native code right now.”
Add sandboxing, compiler hardening, and runtime mitigations. Target hot spots incrementally. - “Customers want proof quickly during incidents.”
Publish version-specific status with SBOM snippets and remediation timelines. Avoid vague statements.
How to measure progress
Program-level KPIs
- SBOM coverage (% builds with SBOM) and freshness (median days since generation)
- Median days-to-update for high-risk dependencies
- Vulnerability MTTR by severity; % critical >7 days (should trend toward 0)
- % artifacts with valid signatures and verifiable provenance
- % artifacts reproducible across independent rebuilds
- % new code written in memory-safe languages; year-over-year trend in memory-related bugs
- Fuzzing crashes found/fixed and coverage
- Incident response: time to inventory impact, time to 90% deployment of fixes
Qualitative signals
- Fewer last-minute hotfixes before releases
- Faster upstream collaboration and more merged PRs
- Shrinking exception backlog and better audit outcomes
A simple 4-week starter plan (first 30 days)
Week 1: Visibility sprint
- Generate SBOMs for one flagship service and publish them with builds.
- Turn on SCA scanning in CI and schedule a nightly production registry scan.
- Draft a one-page policy with patch SLAs and publish it internally.
Week 2: Automation sprint
- Enable update automation for application deps and base images.
- Add CI gates that fail builds when critical vulnerabilities are detected.
- Pilot provenance generation and attach attestations to release artifacts.
Week 3: Integrity sprint
- Enable image signing in CI; enforce verification in staging.
- Containerize the build for one repo to begin reproducibility work.
- Add a 10-minute fuzz job for a high-risk parser.
Week 4: Response sprint
- Run an SBOM-driven incident drill using a recent, high-profile CVE.
- Record timeline metrics and update the policy or tooling based on findings.
- Present a 30-minute readout to leadership with KPIs and next-quarter goals.
Frequently asked questions
- Is open source inherently less secure than closed source?
No. Security depends on processes and practices, not licensing. Open code enables independent review and faster community fixes, but only helps if you track components and update promptly. - Which SBOM format should we use—SPDX or CycloneDX?
Use whichever your tools support best; both are widely adopted. Standardize on one internally to simplify automation, and convert if a partner needs the other. - How do we avoid drowning in vulnerability alerts?
Focus on exploitability and business impact, deduplicate findings, use VEX where applicable, and enforce severity-based SLAs. Start with internet-facing services and high-risk packages. - Do we really need to sign artifacts if we already trust our CI?
Yes. Signatures provide portable trust that follows artifacts into registries and customer environments. They also give you a public audit trail of releases. - Is provenance verification overkill for smaller teams?
Not if you automate it. Emitting and checking provenance is increasingly straightforward, and it closes a critical supply-chain gap with minimal overhead once configured. - We can’t switch everything to a memory-safe language. What now?
Adopt memory-safe code for new components, sandbox legacy code, and use compiler hardening and sanitizers. Target the hottest risk areas first. - How do reproducible builds help if we already sign artifacts?
Signatures say who produced an artifact. Reproducibility lets others show that the artifact truly came from the published source and build recipe—defense-in-depth. - What if a critical dependency is abandoned?
Fork as a last resort, but first try to recruit new maintainers, sponsor maintenance, or replace the component. If you fork, set a time-boxed plan to return upstream or migrate. - How often should we run fuzzing?
Per-commit smoke fuzzing for a few minutes, plus deeper nightly runs. Prioritize parsers and components that handle untrusted input. - What’s the fastest way to start if we have no tooling?
Turn on update automation, generate SBOMs in CI, and scan nightly. These three steps deliver outsized results within days. - Do SBOMs create legal or disclosure risks?
Treat SBOMs like any other sensitive operational artifact. Share externally when appropriate (e.g., with customers under NDA) and maintain internal access controls. - How do we show customers we’re serious about open-source security?
Publish signed releases, provide SBOMs and provenance on request, share patch timelines during incidents, and document your policy, SLAs, and automation.
Conclusion
Open source multiplies what teams can build—and what attackers can exploit. The decisive factor isn’t whether your code includes open source; it’s how you consume, verify, update, and contribute. Inventory with SBOMs. Choose healthier dependencies. Automate scanning and updates. Prove provenance. Sign and verify artifacts. Make builds reproducible. Favor memory-safe code. Fuzz aggressively. And practice incident response that starts with search, not panic. Do these consistently, and transparency becomes a competitive security advantage rather than a liability.
Copy-ready CTA: Start today: enable SBOMs in CI for one service, turn on update automation, and sign your next release.
References
- 2025 Open Source Security and Risk Analysis report (PDF) — Synopsys / Black Duck; April 2025. https://www.blackduck.com/content/dam/black-duck/en-us/reports/rep-ossra.pdf
- Open source trends: 2025 OSSRA findings — Black Duck Blog; February 25, 2025. https://www.blackduck.com/blog/open-source-trends-ossra-report.html
- New report finds 74% of codebases contained high-risk open source vulnerabilities — Synopsys Newsroom; February 27, 2024. https://investor.synopsys.com/news/news-details/2024/New-Synopsys-Report-Finds-74-of-Codebases-Contained-High-Risk-Open-Source-Vulnerabilities-Surging-54-Since-Last-Year/default.aspx
- Secure by Demand Guide: How software customers can hold manufacturers accountable (PDF) — Cybersecurity and Infrastructure Security Agency; August 6, 2024. https://www.cisa.gov/sites/default/files/2024-08/SecureByDemandGuide_080624_508c.pdf
- Secure by Design (program overview and resources) — Cybersecurity and Infrastructure Security Agency; accessed August 2025. https://www.cisa.gov/securebydesign
- Supply-chain Levels for Software Artifacts (SLSA) — slsa.dev; accessed August 2025. https://slsa.dev/
- SLSA specification: levels — slsa.dev; accessed August 2025. https://slsa.dev/spec/v1.0/levels
- SPDX specifications (ISO/IEC 5962:2021) — SPDX Project; accessed August 2025. https://spdx.dev/use/specifications/
- SPDX Specification v3.0.1 — SPDX Project; 2024. https://spdx.github.io/spdx-spec/v3.0.1/
- CycloneDX specification overview — CycloneDX; July 11, 2024. https://cyclonedx.org/specification/overview/
- CycloneDX Bill of Materials Standard (ECMA-424) — OWASP CycloneDX; accessed August 2025. https://owasp.org/www-project-cyclonedx/
- Authoritative Guide to SBOM (PDF) — CycloneDX; June 25, 2023. https://cyclonedx.org/guides/OWASP_CycloneDX-Authoritative-Guide-to-SBOM-en.pdf
- Sigstore: project overview — Sigstore Docs; accessed August 2025. https://docs.sigstore.dev/about/overview/
- How identity-based (“keyless”) signing works — Sigstore Docs; accessed August 2025. https://docs.sigstore.dev/cosign/signing/overview/
- Reproducible Builds: overview — Reproducible-builds.org; accessed August 2025. https://reproducible-builds.org/
- Monthly reports (activity and news) — Reproducible-builds.org; January 2025 and ongoing. https://reproducible-builds.org/news/













2 Comments