Blockchain as a service brings the power of distributed ledgers to your projects without the burden of building and operating complex infrastructure. In plain terms, you subscribe to a hosted platform that runs blockchain nodes, secures the network, and exposes APIs and tools so you can deploy smart contracts, connect applications, and govern membership. If you want the short version: choose a permission model (public vs. permissioned), shortlist vendors by protocol support and compliance, pilot with realistic traffic, then scale with clear SLAs and cost guardrails. Done well, this approach reduces time-to-value, improves uptime, and lets your team focus on product outcomes rather than server chores.
Fast path checklist: define the use case; pick permissioned or public; select protocol (e.g., Hyperledger Fabric, Corda, Quorum/Besu); evaluate managed services and regions; run a 2–4 week pilot with synthetic and sample production data; lock observability, keys, and SLAs; plan for governance and upgrades. You’ll finish with a working network, measurable throughput, and a cost envelope you can defend.
Below, you’ll find 11 credible blockchain as a service (BaaS) companies, each explained in practical terms—what they’re best for, how they work, what numbers to watch, common pitfalls, and tools you can try. Use them as a menu: pick the platform that fits your architecture and risk profile, not the other way around.
1. Amazon Web Services — Amazon Managed Blockchain (Hyperledger Fabric)
If your team already builds on AWS, Amazon Managed Blockchain (AMB) is a natural starting point for permissioned networks built on Hyperledger Fabric. AMB handles the heavy lifting: certificate authorities, ordering service, peer node lifecycles, metrics, and scaling. You can spin up members (organizations), provision peer nodes with storage, set up channels, and start deploying chaincode without wrangling Kubernetes, certificates, or gossip protocols by hand. Pricing reflects a cloud-native model—you pay by the second for peer nodes, add storage, and dial up or down as your pilot evolves. The net effect is faster experiments and lower operational risk, especially when your org already has guardrails for IAM, networking, and KMS on AWS.
Why it matters
- Speed to first transaction: standing up a permissioned Fabric network from scratch is non-trivial; AMB cuts setup from weeks to hours.
- AWS-native security: reuse IAM roles, VPCs, KMS keys, and CloudWatch for a familiar security posture.
- Elastic economics: pay-per-second peer nodes suit pilots and bursty workloads; you avoid over-provisioning.
How it works (at a glance)
- Create or join a Fabric network and map each membership to your organization.
- Provision peer nodes, a CA, and channels; deploy chaincode packages and endorsement policies.
- Integrate apps through Fabric SDKs; monitor with CloudWatch metrics and logs.
Numbers & guardrails (example)
- Pilot shape: 3 organizations × 1 peer each, 500 GB total peer storage, ~100 tx/s peak during tests.
- Cost sanity check: start with minimal peer sizes; scale only after profiling read/write sets and endorsement paths.
- Latency: co-locate app clients and peers in the same region/AZ to keep endorsement and ordering roundtrips tight.
Common mistakes
- Over-complicated endorsement policies that add latency and lower throughput.
- Treating CA operations casually—rotate and back up CA roots and intermediates with the same discipline as app keys.
- Ignoring channel design; a “one-channel-for-everything” pattern creates governance bottlenecks.
Bottom line: AMB is a strong default for Fabric on AWS—especially when you need enterprise identity, private channels, and cloud-native ops without deep Fabric internals on day one. AWS Documentation
2. IBM Blockchain Platform (Hyperledger Fabric)
IBM Blockchain Platform packages Hyperledger Fabric into a managed, enterprise-grade stack you can deploy across supported orchestrators (including OpenShift and Kubernetes) and run with consistent tooling. It focuses on governance, identity, and robust dev-to-prod workflows: operate multiple organizations, set endorsement policies, manage chaincode lifecycles, and integrate with enterprise identity providers. For teams coming from regulated industries or needing IBM’s services bench, the offering provides a clear line from proof-of-concept to consortium operations with production-level observability and support. The Fabric base means you get mature concepts—channels for data isolation, MSPs for identity, and pluggable consensus—wrapped in standardized management.
Why it matters
- Enterprise governance: practical tooling for membership onboarding, chaincode upgrades, and channel management.
- Hybrid flexibility: deploy in environments you already trust, then add new orgs without reinventing the stack.
- Identity rigor: permissioned access with cryptographic identity and auditable policies.
Tools/Examples
- Visual tools for creating channels and installing/approving chaincode.
- Deployment patterns for multi-org testing before consortium rollout.
- Documentation and runbooks covering Fabric CA, endorsement, and validation flows.
Numbers & guardrails (example)
- Throughput expectations: Fabric commonly sustains tens to low hundreds of tx/s per channel with standard endorsement; parallelize via multiple channels when needed.
- Operational rhythm: plan quarterly upgrade windows for chaincode and Fabric minor releases to keep security posture fresh while avoiding surprise drift.
Common mistakes
- Neglecting chaincode versioning and endorsement policy migrations.
- Using one channel for six unrelated business processes—split along data-sharing boundaries to reduce blast radius.
Bottom line: If you want permissioned, auditable networks with IBM’s governance and support DNA, this platform gives you Fabric’s strengths with enterprise-ready operations. IBM
3. Oracle Blockchain Platform (OCI)
Oracle Blockchain Platform gives you a pre-assembled, managed Fabric environment on Oracle Cloud Infrastructure (OCI), oriented toward tamper-evident data sharing across partners with built-in REST APIs, monitoring, and integration points. If your core systems already run on Oracle databases and apps, the platform can be a pragmatic bridge—smart contracts automate multi-party workflows while OCI services handle identity, networking, and data services. The managed experience includes console-driven network creation, role management, and out-of-the-box endpoints for invoking chaincode, so developers can wire prototypes quickly and iterate toward production without bespoke ops plumbing.
Why it matters
- First-class OCI integration: networking, IAM, and observability flow with existing Oracle estates.
- Prebuilt REST access: invoke and query chaincode with fewer SDK hurdles.
- Data assurance: immutability plus endorsement reduces reconciliation work between partners.
How to do it
- Launch a Blockchain Platform instance; define users and assign roles.
- Create channels that match data-sharing relationships; deploy chaincode aligned to those domains.
- Use the REST API to integrate business systems; stream events into analytics.
Numbers & guardrails (example)
- Resilience target: aim for multi-AZ peer distribution for read resilience; keep ordering service redundant.
- Transaction size: trim writes to essential fields; large payloads lower throughput and inflate storage.
Common mistakes
- Trying to treat the ledger as a document store; persist payload footprints and keep bulk in object storage.
- Skipping formal endorsement policies—start strict, revisit performance after baseline measures.
Bottom line: For Oracle-heavy shops, this service offers a managed Fabric with practical REST interfaces and predictable OCI operations.
4. Kaleido (Multi-protocol: Fabric, Besu, Quorum, Corda, and more)
Kaleido is a flexible, enterprise-grade platform that lets you deploy and operate networks across multiple protocols—Hyperledger Fabric, Hyperledger Besu, GoQuorum, Corda, and popular EVM chains—on AWS or Azure. Its appeal is breadth and orchestration: one control plane to spin up nodes, provision identities, configure private transactions, manage token services, and expose enterprise-friendly APIs. For teams that haven’t yet locked into a single protocol—or that need to run multiple ledgers for different business lines—Kaleido reduces orchestration toil and enables a consistent way to provision networks, environments, and CI/CD flows.
Why it matters
- Protocol choice without chaos: switch between Fabric privacy and EVM programmability as needs evolve.
- Multi-cloud footprint: deploy in the cloud you already use, or span clouds for partner neutrality.
- Full-stack support: identity, private transactions, and data planes packaged for enterprise developers.
Tools/Examples
- Hyperledger FireFly stack support for eventing, off-chain data, and tokenization.
- Templates to bootstrap permissioned EVM networks with private TX (Tessera) and fine-grained roles.
- Marketplace listings for quick procurement on your preferred cloud.
Numbers & guardrails (example)
- Pilot topology: 2 clouds × 3 orgs × 1 node/org to model cross-enterprise latency and governance.
- Throughput tuning: for EVM networks, start with Istanbul BFT or QBFT consensus for faster finality; for Fabric, right-size endorsement to the minimal set of orgs.
Common mistakes
- Underestimating cross-cloud egress costs and inter-org latency—measure with real traffic early.
- Mixing unrelated use cases on the same chain; isolate by domain to scale independently.
Bottom line: Kaleido is ideal when you want one pane of glass for heterogeneous enterprise blockchain stacks across clouds and protocols. Microsoft Marketplace
5. R3 Corda (Managed and Cloud-Native Deployments)
Corda is a permissioned distributed ledger designed for regulated markets where privacy, bilateral flows, and legal finality matter. Rather than broadcasting all transactions network-wide, Corda shares data on a need-to-know basis, which fits financial agreements, trade finance, and asset tokenization. R3 and partners support managed deployments and cloud-native operations, with orchestration that accommodates vertical scaling (bigger VMs) and horizontal patterns via Kubernetes. If your problem looks like “digitize an existing legal workflow with strong privacy and notary-based finality,” Corda’s model often maps cleanly.
Why it matters
- Privacy by design: counterparties see only relevant data, protecting commercial sensitivity.
- Ecosystem fit: built for institutions, with concepts like notaries and flows that mirror real agreements.
- Operational clarity: flexible scaling and container-friendly runtimes.
Numbers & guardrails (example)
- Sizing idea: start a notary with 4–8 vCPU and 16–32 GB RAM; increase for high agreement volumes.
- Flow latency: expect lower p95 when counterparties are region-proximate; keep notaries close to participant clusters.
- Throughput: for bilateral workflows, focus on flow concurrency and persistence tuning rather than pure TPS.
Common mistakes
- Treating Corda like a broadcast blockchain; design flows around bilateral or limited-party transactions.
- Overlooking legal prose and envelope models—tie states to clear contract terms to simplify audits.
Bottom line: Choose Corda when your core requirement is confidential, legally meaningful workflows across institutions with managed, production-oriented operations. R3
6. ConsenSys — Quorum/Besu & Infura (Managed Nodes and Enterprise Ethereum)
ConsenSys maintains enterprise Ethereum stacks—GoQuorum for permissioned EVM networks and Hyperledger Besu—alongside developer infrastructure such as Infura for reliable, scalable RPC access to public networks. This combination covers both sides: build private EVM networks with transaction privacy and enterprise consensus, and connect public-facing apps to Ethereum-compatible chains through managed endpoints with robust SLAs. If you need Solidity and EVM tooling but require private transactions or permissioned membership, Quorum/Besu align well; if you’re shipping consumer apps, Infura reduces the undifferentiated work of running highly available, globally distributed nodes.
Why it matters
- EVM familiarity: Solidity, tooling, and libraries carry over to permissioned deployments.
- Privacy features: private TX managers (e.g., Tessera) support selective disclosure among parties.
- Production RPC: Infura provides stable endpoints and historical data access for many networks.
Tools/Examples
- Quorum dev quickstarts; Besu enterprise features and permissioning.
- Infura multi-network endpoints (Ethereum and other chains) with dashboards and usage analytics.
Numbers & guardrails (example)
- RPC budgeting: start with 5–10 million requests/day for early-stage apps; shard reads across endpoints when you approach p95 latency limits.
- Private TX footprint: test with payloads under tens of KB to keep privacy overhead predictable.
Common mistakes
- Relying solely on public RPC for write-heavy flows—introduce dedicated nodes or burst buffers.
- Skipping permission models in a “semi-private” network; formalize org-level accounts and roles.
Bottom line: ConsenSys is the go-to for EVM everywhere—permissioned with Quorum/Besu and public connectivity with Infura—when you want Ethereum’s developer experience with enterprise controls. Consensys – The Ethereum Company
7. Google Cloud — Blockchain Node Engine (Managed Nodes)
Google Cloud’s Blockchain Node Engine (BNE) focuses on running dedicated nodes for selected blockchain networks with managed provisioning, security hardening, and straightforward APIs for connecting applications. It’s not a permissioned-network toolkit; rather, it’s “nodes-as-a-service” with Google’s security patterns (VPC, IAM, CMEK) and lifecycle management. For teams that need reliable, high-performance RPC or validator nodes without building their own SRE bench, BNE can be a clean way to get predictable operations, auditability, and integration with Google’s observability stack.
Why it matters
- Operational focus: one-click provisioning, backups, and upgrades reduce ops toil.
- Security posture: API keys, IAM, private networking, and CMEK suit enterprise risk appetites.
- Data locality: choose regions close to users or partners to shave off latency.
How to do it
- Create nodes, secure API keys, and wire endpoints into app back ends.
- Use load-balancing patterns for read scaling; isolate write paths to nodes with higher IOPS.
- Stream logs and metrics into Cloud Logging and Monitoring for alerting.
Numbers & guardrails (example)
- Baseline: plan for 100–500 requests/second per node for read-heavy dapps; add nodes as p95 grows.
- Cost sanity: estimate with the BNE pricing calculator; reserve capacity for steady workloads, burst on demand otherwise.
Common mistakes
- Mixing public RPC and private workloads without proper rate limiting—partition traffic.
- Under-investing in observability; set budgets and alerts for request spikes to avoid bill shock.
Bottom line: If you need managed, enterprise-grade RPC or dedicated nodes on Google Cloud with minimal ops, BNE is a pragmatic fit—pair it with your preferred L2s and app stacks.
8. Blockdaemon (Dedicated Nodes, APIs, and Staking)
Blockdaemon specializes in institutional-grade node infrastructure, offering Dedicated Nodes for many protocols, developer APIs, and staking operations. Think of it as a one-stop shop for reliable nodes, SLAs, and compliance-friendly operations without owning the hardware or hiring a 24/7 on-call team. If you’re building production dapps or institutional services and need dedicated capacity rather than shared endpoints, this model gives you configuration control, performance, and audit trails with a commercial support wrapper.
Why it matters
- Dedicated performance: exclusive nodes reduce noisy-neighbor effects; you can tune for your traffic.
- Institutional focus: reporting, governance, and staking services align with regulated operators.
- Protocol breadth: deploy across many chains through one provider.
Tools/Examples
- Native RPC and REST APIs with documentation and sample code.
- Options for single nodes or clustered topologies (e.g., Solana) to improve resilience.
- Dashboards for usage, health, and billing transparency.
Numbers & guardrails (example)
- Latency target: keep p95 under 150–200 ms for user-facing ETH RPC reads; add a read replica in a secondary region if you exceed.
- Availability: aim for multi-zone deployment with automated failover; test it quarterly.
Common mistakes
- Treating dedicated nodes as infinite capacity—profile and scale before traffic spikes.
- Weak key management around validator operations; use HSMs or provider KMS integrations.
Bottom line: Blockdaemon fits teams that want premium, dedicated infrastructure and SLAs for production chains without building a large infra team. blockdaemon.com
9. Chainstack (Global Managed Nodes with 70+ Protocols)
Chainstack provides managed nodes and APIs across a wide and fast-growing list of networks, with an emphasis on performance (geo-load-balancing), uptime, and deep historical data access. It markets itself as a cost-effective alternative that still gives you dedicated and elastic options, multi-region endpoints, and developer-friendly tooling. If your priority is multi-chain reach with predictable latency and you want to avoid the complexity of self-hosting, Chainstack is worth a close look—especially for teams iterating across L1/L2s and needing straightforward provisioning and scaling. Chainstack
Why it matters
- Breadth: support for 70+ protocols makes it easy to experiment or go multi-chain.
- Performance: global load-balancing and high historical throughput reduce cold-start penalties.
- Developer experience: clear dashboards, per-network docs, and elastic → dedicated upgrades.
Tools/Examples
- “Global Nodes” for auto-routed, geo-proximate RPC access.
- Network-specific docs (e.g., Arbitrum Stylus support) for advanced features.
- Usage metering to right-size plans as you scale.
Numbers & guardrails (example)
- Traffic planning: for read-heavy apps, budget 3–8 million requests/day per environment to start; scale after p95 analysis.
- Uptime: design assuming ≥99.9% with occasional network-level incidents; build client retries with backoff.
Common mistakes
- Treating multi-chain RPC like a uniform API; different networks have different quirks and limits—read the per-protocol docs.
- Failing to pin critical reads to archival or “deep history” endpoints when you need full state.
Bottom line: Chainstack is a strong multi-chain node platform with good price-performance and global routing that helps teams move quickly across ecosystems. docs.chainstack.com
10. Alibaba Cloud — Blockchain as a Service (BaaS)
Alibaba Cloud’s BaaS is an enterprise PaaS built atop Kubernetes with support for mainstream blockchain engines, including Hyperledger Fabric, AntChain technologies, and Quorum. It targets consortium scenarios common in supply chains and public-sector collaborations, providing consoles for creating consortia, managing organizations, and deploying smart contracts with integrations across Alibaba’s broader cloud services. If your partners or operations sit in regions where Alibaba Cloud is the de facto platform, this service can streamline cross-enterprise networks with familiar governance and identity patterns. Alibaba Cloud
Why it matters
- Regional fit: aligns with ecosystems that rely on Alibaba Cloud services and compliance frameworks.
- Consortium tooling: built-in workflows for multi-org setups reduce the friction of onboarding partners.
- Kubernetes foundation: predictable scaling and resilience patterns for production networks.
How to do it
- Use the BaaS console to create a consortium and invite member organizations.
- Define chaincode deployment pipelines, endorsement policies, and channel layouts per business process.
- Integrate with Alibaba’s security services for key management and auditing.
Numbers & guardrails (example)
- Consortium cadence: plan onboarding in batches of 2–3 organizations to stabilize policies and avoid channel churn.
- Payload sizing: keep ledger writes lean; store large artifacts in object storage and commit hashes on-chain.
Common mistakes
- Designing one monolithic consortium for unrelated workflows—split by value stream to keep governance nimble.
- Under-estimating cross-region latency; locate peers near participants when endorsement spans multiple regions.
Bottom line: Alibaba Cloud BaaS offers a managed, consortium-friendly platform for Fabric/Quorum-style deployments where Alibaba is the primary cloud. Alibaba Cloud
11. Tencent Cloud — TBaaS (Transaction Blockchain as a Service)
Tencent Cloud’s TBaaS provides a hosted platform for building and running permissioned blockchain networks, with support for engines such as Hyperledger Fabric and ChainMaker. It emphasizes end-to-end service—console-based provisioning, monitoring, and elastic scaling—so organizations can focus on smart contracts and business integration instead of cluster care. For enterprises in APAC or collaborating with Tencent’s ecosystem, TBaaS can deliver a practical, managed baseline with governance features and documentation tailored to common cross-industry scenarios.
Why it matters
- Engine choice: Fabric and local engines like ChainMaker cover diverse regulatory and performance needs.
- Hosted simplicity: the public cloud version is fully hosted—scale nodes without pre-purchasing raw compute.
- Compliance alignment: documentation and features speak to regional regulatory patterns and data controls.
Tools/Examples
- Console views for CPU, memory, disk, and network, plus scale-out when throughput rises.
- Guidance for sector use cases (e.g., supply chain, digital justice systems) that map to TBaaS primitives.
Numbers & guardrails (example)
- Sizing idea: start with 3–5 endorsing peers across member orgs; co-locate notaries/orderers with the busiest peers.
- Operations: set alerts on ledger storage growth; plan compaction and archive strategies above the 80% threshold.
Common mistakes
- Assuming out-of-the-box cross-chain—TBaaS focuses on single-network excellence; integrate third-party bridges if required.
- Copy-pasting policies from public chains; tune Fabric/ChainMaker consensus and endorsement for your data-sharing model.
Bottom line: TBaaS is a credible managed platform for permissioned networks in Tencent Cloud regions, with engine flexibility and full-service operations for consortium use cases. staticintl.cloudcachetci.com
Quick Fit Matrix (skim this, then dive deeper)
| Vendor | Best For | Example Protocols | Hosted Focus |
|---|---|---|---|
| AWS AMB | Permissioned Fabric on AWS with IAM/KMS | Hyperledger Fabric | Managed consortium + ops |
| IBM | Fabric with governance tooling & support | Hyperledger Fabric | Managed & hybrid |
| Oracle | OCI-native Fabric + REST integration | Hyperledger Fabric | Managed consortium |
| Kaleido | Multi-protocol, multi-cloud orchestration | Fabric, Besu, Quorum, Corda | Full-stack |
| R3 Corda | Confidential bilateral flows in finance | Corda | Managed/partner ops |
| ConsenSys | EVM permissioned + public RPC | GoQuorum, Besu, Infura | Hybrid stack |
| Google BNE | Managed nodes/RPC on GCP | Ethereum and others (varies) | Nodes-as-a-service |
| Blockdaemon | Dedicated nodes with SLAs | Many L1/L2s | Dedicated nodes |
| Chainstack | Multi-chain managed RPC + global routing | 70+ protocols | Elastic + dedicated |
| Alibaba Cloud | Consortium networks on Alibaba | Fabric, Quorum, AntChain | Managed BaaS |
| Tencent Cloud | APAC permissioned networks | Fabric, ChainMaker | Fully hosted BaaS |
(Matrix summarizes positioning; verify protocol availability per vendor before final selection.) Tencent CloudAmazon Web Services, Inc.IBM
Conclusion
Choosing the right blockchain as a service provider starts with your use case, not a brand name. If you need permissioned data sharing with strict identity and endorsement controls, platforms built on Hyperledger Fabric (AWS, IBM, Oracle, Alibaba, Tencent) are straightforward and well-documented. If your workflow is bilateral and privacy-sensitive in financial markets, Corda is purpose-built. If you want the EVM developer experience with either public or private footprints, ConsenSys (Quorum/Besu + Infura) and Kaleido provide flexible paths. And if your primary challenge is operating reliable nodes with enterprise security, Google’s Node Engine, Blockdaemon, and Chainstack remove the day-2 ops tax so you can ship faster.
A practical next step is to run a time-boxed pilot: select two vendors that fit your protocol and region, mirror a real workload, and instrument latency, throughput, and failure modes. Keep payloads lean, endorsement policies tight, and keys in managed HSM/KMS from day one. Above all, design for governance—who can join, who can read what, and how upgrades happen—so your network doesn’t stall when success brings more partners to the table. Ready to move? Shortlist two providers today, set up a two-week test plan, and measure your way to a confident decision.
FAQs
1) What is blockchain as a service in one sentence?
It’s a hosted platform that runs blockchain infrastructure and tooling for you—nodes, security, APIs—so you can deploy smart contracts and connect applications without building the underlying network yourself.
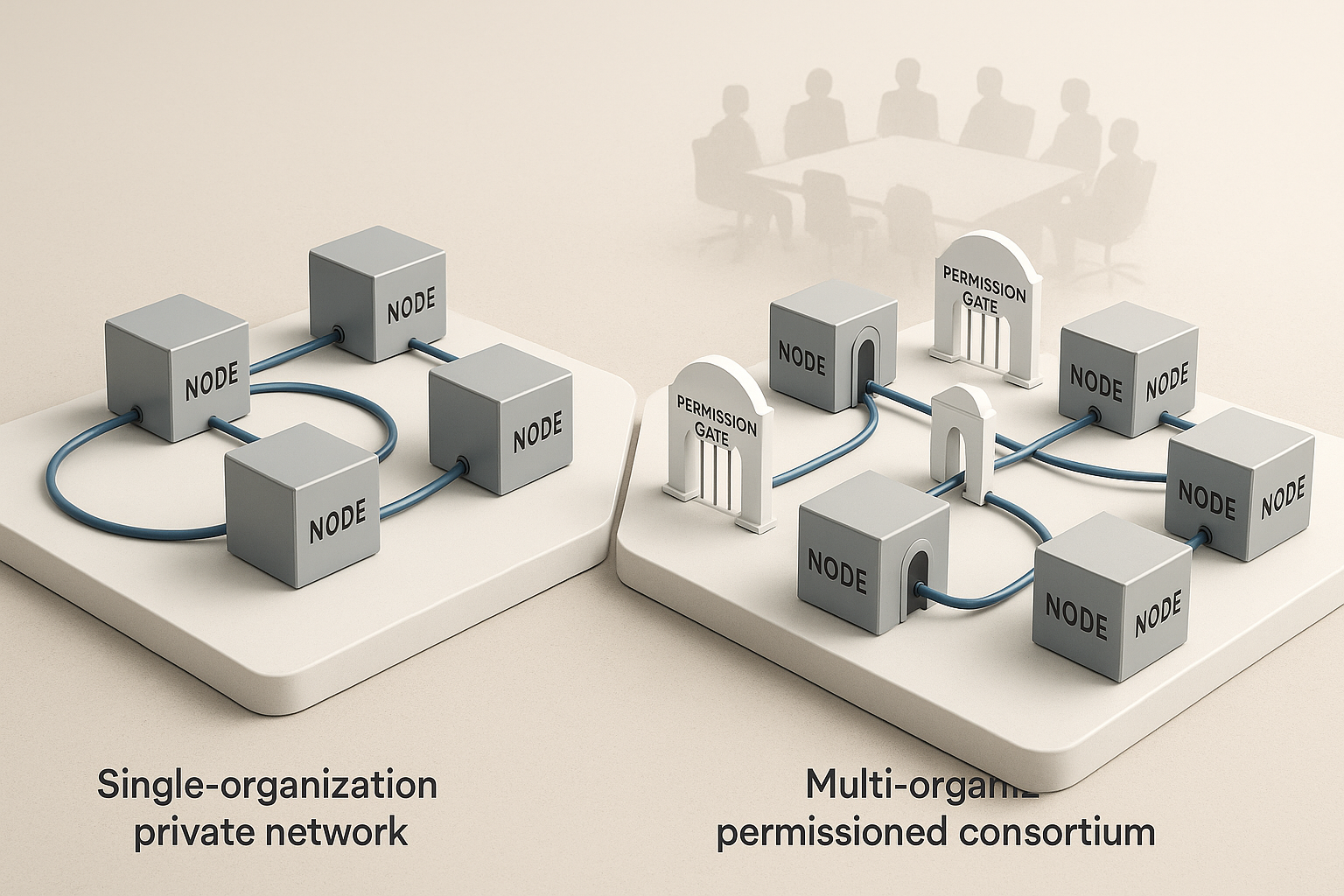
2) How do I choose between public and permissioned networks?
Pick public when you need open participation and token-based interactions; pick permissioned when you need named organizations, access control, private data, and enterprise governance. Many teams mix both: a permissioned core for sensitive workflows plus public rails for customer-facing features.
3) Which protocols dominate enterprise BaaS?
Hyperledger Fabric and Corda lead for permissioned use cases, while GoQuorum/Besu provide an EVM-compatible path with privacy. The right fit depends on data-sharing patterns, privacy needs, and developer skills.
4) What are realistic performance expectations?
With sensible design, permissioned networks commonly sustain tens to low hundreds of transactions per second per channel or flow. You scale by adding channels/flows, right-sizing endorsement or consensus, and optimizing payloads and persistence.
5) How should I budget?
Start small: a handful of nodes, modest storage, and conservative request volumes. Expect costs to be driven by node size, storage growth, and ingress/egress. Build dashboards and alerts to flag request spikes and ledger expansion.
6) Do I need smart contracts for everything?
No. Keep business logic on-chain only when you need shared state, deterministic execution, or automated multi-party rules. Large files and analytics should live off-chain, with hashes or pointers on-chain for integrity.
7) How do identity and access work?
Permissioned networks use cryptographic identities and roles (e.g., Fabric MSPs, Corda identities). Define who can endorse, read, and write at the organization level, then map users and apps to those roles via CAs and IAM.
8) What’s the difference between nodes-as-a-service and full BaaS?
Nodes-as-a-service runs and maintains blockchain nodes with APIs (great for public networks). Full BaaS adds consortium management, private data constructs, chaincode/contract lifecycles, and governance tooling for permissioned networks.
9) Can I switch protocols later?
It’s possible but non-trivial. Choose protocols that match your data model and privacy from the start. If you foresee multiple needs, consider orchestration platforms (e.g., Kaleido) that support more than one engine to hedge future changes.
10) How do I handle upgrades without downtime?
Plan maintenance windows, version contracts with feature flags, and keep rollback paths. For Fabric, coordinate chaincode approvals; for EVM, use proxies or immutability patterns that allow safe migration.
11) What security basics should be non-negotiable?
Hardware-backed key storage (HSM/KMS), private networking, access logs, least-privilege IAM, signed releases for node software, and regular audits. Treat CAs and notaries/orderers as crown jewels.
12) What’s a good pilot success metric?
A working end-to-end transaction under target p95 latency with three realistic failure drills (node loss, network partition, contract bug) successfully handled by your runbooks—plus a clear governance doc ratified by all members.
References
- Amazon Managed Blockchain Documentation — Hyperledger Fabric; Amazon Web Services; https://docs.aws.amazon.com/managed-blockchain/
- Amazon Managed Blockchain — Pricing; Amazon Web Services; https://aws.amazon.com/managed-blockchain/pricing/
- IBM Blockchain Platform — Getting Started; IBM; https://www.ibm.com/docs/en/blockchain-platform/2.5.3
- Hyperledger Fabric Documentation; Hyperledger Foundation; https://hyperledger-fabric.readthedocs.io/
- Oracle Blockchain Platform — Cloud Service; Oracle; https://www.oracle.com/blockchain/cloud-platform/
- Oracle Blockchain Platform — Documentation; Oracle; https://docs.oracle.com/en/cloud/paas/blockchain-cloud/
- Kaleido — Enterprise-Grade Blockchain & Digital Asset Platform; Kaleido; https://www.kaleido.io/
- Kaleido on Microsoft Azure — Overview; Microsoft Commercial Marketplace / Kaleido; https://marketplace.microsoft.com/en-us/marketplace/apps/kaleidoinc1626787540168.kaleido
- R3 Corda — Platform Overview; R3; https://r3.com/r3-labs/corda/
- Get Corda & FAQs; R3; https://r3.com/get-corda/corda-faqs/
- ConsenSys — Quorum (GoQuorum) Docs; ConsenSys; https://goquorum.readthedocs.io/
- Infura — Web3 Development Platform; ConsenSys; https://www.infura.io/
- Google Cloud — Blockchain Node Engine; Google Cloud; https://cloud.google.com/blockchain-node-engine
- Google Cloud — Blockchain Node Engine Docs; Google Cloud; https://docs.cloud.google.com/blockchain-node-engine/docs
- Blockdaemon — Dedicated Nodes; Blockdaemon; https://www.blockdaemon.com/nodes/dedicated-nodes
- Blockdaemon — Docs; Blockdaemon; https://docs.blockdaemon.com/
- Chainstack — Protocols; Chainstack; https://chainstack.com/protocols/
- Chainstack — Global Nodes; Chainstack; https://chainstack.com/global-nodes/
- Alibaba Cloud — Blockchain as a Service; Alibaba Cloud; https://www.alibabacloud.com/en/product/baas
- Alibaba Cloud — What is BaaS?; Alibaba Cloud; https://www.alibabacloud.com/help/en/blockchain-as-a-service/latest/what-is-baas
- Tencent Cloud — TBaaS; Tencent Cloud; https://www.tencentcloud.com/products/tbaas
- Tencent Cloud — TBaaS Overview; Tencent Cloud Docs; https://www.tencentcloud.com/document/product/1258/69033