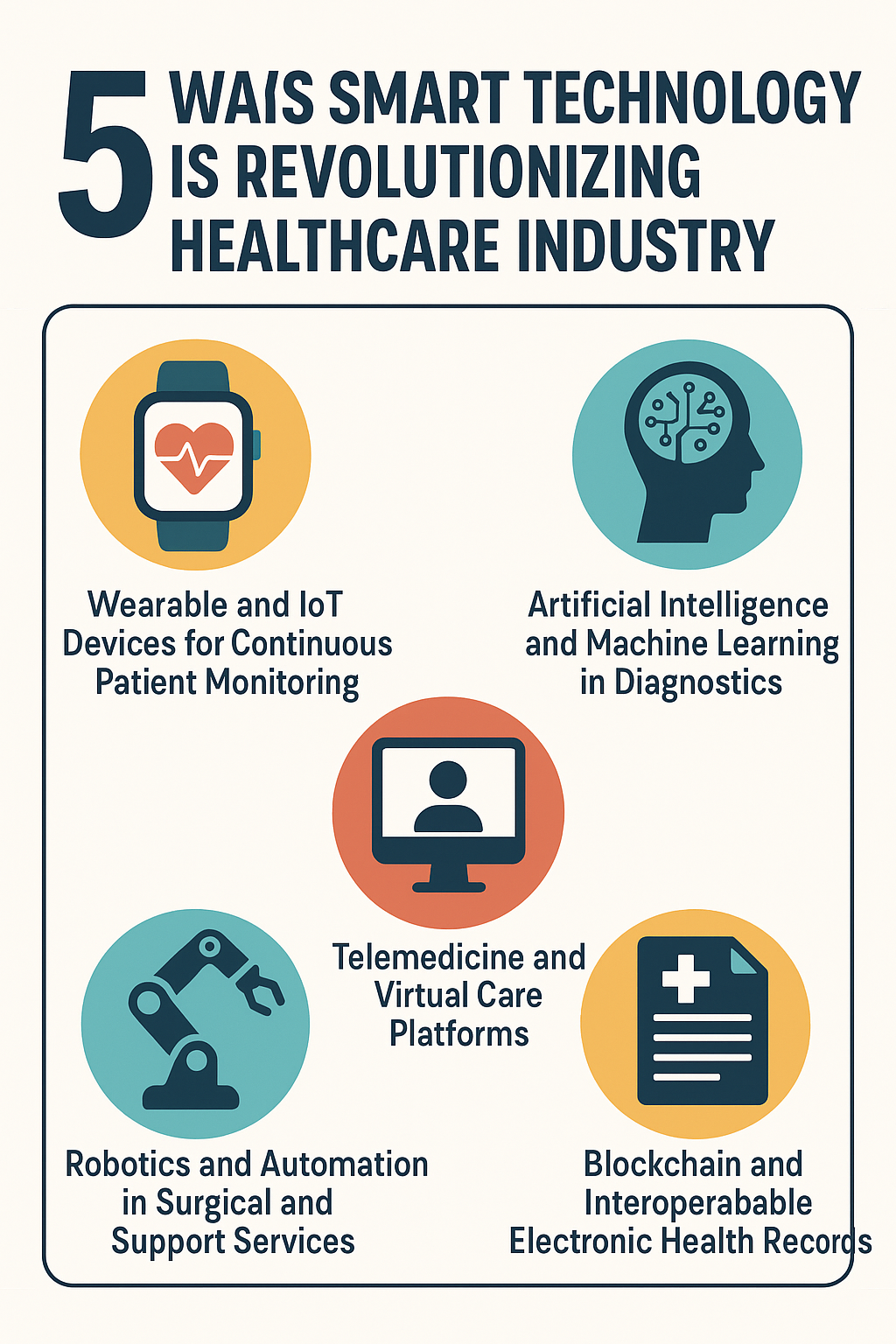
Artificial intelligence is no longer a distant promise in medicine—it’s already inside clinics, operating rooms, and research labs, reshaping how care is delivered. In the next few years, five developments will define where the technology truly matters: imaging and diagnostics, generative documentation, predictive analytics at the bedside, accelerated drug discovery, and patient-facing AI for remote care. This article unpacks what each is, why it matters, how to get started, how to measure results, and how to stay safe while you scale.
Disclaimer: The following is general information and not medical or legal advice. For clinical or regulatory decisions, consult qualified professionals who can evaluate your specific context.
Key takeaways
- Imaging AI is moving from pilot to practice, improving detection and speeding workflows when paired with rigorous oversight and quality assurance.
- Generative AI “ambient” documentation tools can cut administrative time and reduce burnout—if you implement consent, review, and error-tracking processes.
- Predictive analytics for conditions like sepsis can shorten time-to-treatment, but outcome benefits vary; calibration, bias checks, and alert hygiene are essential.
- AI is compressing drug discovery cycles, from target identification to trial design—most impact comes when computational hits are tied to disciplined wet-lab validation.
- Patient-facing AI and remote monitoring expand access and catch early deterioration, yet must be paired with clear escalation rules and human oversight.
1) AI-Assisted Imaging and Diagnostics
What it is and why it matters
AI systems analyze medical images (mammograms, chest X-rays, retinal photos, CT/MRI, pathology slides) to flag abnormalities, prioritize worklists, or even render autonomous decisions in narrow use cases. In breast screening programs and other domains, real-world deployments show that AI can raise detection rates without increasing unnecessary recalls when applied as a second reader or workflow triage. In ophthalmology, autonomous diagnostic tools for diabetic retinopathy created a precedent that brought specialty-level screening into primary care settings. These shifts matter because imaging workloads keep rising while expert capacity lags.
Core benefits
- Faster case prioritization and reduced backlogs.
- More consistent sensitivity in high-volume screening tasks.
- Earlier detection in programs with constrained reader supply.
- Potential to expand access in underserved settings via point-of-care imaging.
Requirements and prerequisites
- Data & systems: PACS/RIS and EHR integration; DICOM routing; a sandbox environment for validation.
- Governance: A multidisciplinary evaluation committee (radiology, pathology, quality, ethics, IT security, compliance).
- Compute: On-prem GPUs or secure cloud inference; logging and audit trails.
- People: Clinician champions, imaging physicists, analysts for quality metrics.
- Budget range: From subscription per-study fees to enterprise licenses.
- Low-cost alternatives: Cloud-hosted tools for a single modality (e.g., chest X-ray triage), reader-assist overlays instead of full automation, and open-source viewers combined with commercial AI APIs delivered through a vendor-neutral archive.
Step-by-step implementation (beginner-friendly)
- Pick one use case with clear ground truth (e.g., screening mammography or diabetic retinopathy) and specify your target metric (e.g., increased cancer detection rate without higher recall, or sensitivity at fixed specificity).
- Assemble a reference dataset from your institution; de-identify and stratify by scanner model, site, and demographics to check generalization.
- Run a silent pilot (AI runs in the background; clinicians blinded). Compare AI outputs with final reports to estimate local performance.
- Decide human-in-the-loop policy: second reader, triage, or autonomous decision with confirmatory safeguards, depending on indication and regulatory status.
- Integrate into workflow: one-click launch in the viewer, structured findings, and standardized alerts.
- Train users on limits, common failure modes, and how to report issues.
- Launch with monitoring: track sensitivity/specificity, recall, positive predictive value, and turnaround time.
- Review monthly in a safety committee; recalibrate thresholds if drift is detected.
Beginner modifications and progressions
- Simplify: Start as a worklist triage (flagging suspected positives for faster review) versus automated reads.
- Progress: Move to AI-supported double reading or autonomous screening only after your metrics are stable and a formal risk assessment is complete.
- Scale: Add modalities one at a time (e.g., from mammography to chest X-ray, then CT).
Recommended frequency, duration, and metrics
- QA frequency: Monthly performance dashboards; quarterly bias and drift reviews; annual revalidation.
- KPIs: Cancer detection rate, recall rate, report turnaround time, false positives per 1,000 screens, flagged-case review time.
- Target cadence: Aim for <30 seconds added per case for assistive tools; net reporting time should decrease as users learn.
Safety, caveats, and mistakes to avoid
- Overtrust: Don’t let AI suppress a human “second look,” especially on subtle findings.
- Mis-calibration across scanners: Validate per site and per device model; thresholds may need local tuning.
- Alert fatigue: If using triage, cap flagged volume or prioritize by score.
- Unclear accountability: Define who signs the report and how disagreements are adjudicated.
- Equity gaps: Routinely stratify metrics by age, sex, ethnicity, and device vendor.
Mini-plan (sample)
- Step 1: Run a 4-week silent pilot on last quarter’s mammograms; measure local sensitivity at fixed specificity.
- Step 2: If stable, enable reader-assist overlays for one screening site with weekly safety huddles.
- Step 3: After 8 weeks, expand to second site; maintain monthly bias and drift reviews.
2) Generative AI for Clinical Documentation and Ambient Scribing
What it is and why it matters
Ambient scribing tools capture the clinician–patient conversation (with consent), then draft structured notes, orders, and patient instructions. Early adopters report double-digit reductions in documentation time and “after-hours charting,” with many clinicians saying they can finally maintain eye contact and empathy during visits rather than typing. For large care groups, that adds up to thousands of hours returned to patient care.
Core benefits
- Less administrative burden and lower burnout risk.
- More consistent, structured notes mapped to EHR fields.
- Faster turnaround for referrals, prior authorizations, and discharge summaries.
- Opportunities to standardize phrasing that supports billing compliance and quality reporting (with clinician oversight).
Requirements and prerequisites
- Hardware: Clinic-room microphones or smartphone apps; reliable network.
- Software: EHR integration for demographics, problems, meds, allergies; secure speech-to-text and generative models; consent capture.
- Governance: Clear policy on consent, recording retention, access controls, and clinician attestation.
- People: Champions in primary care and one procedural specialty; privacy and compliance review.
- Budget: Per-user per-month licenses; optional premium add-ons for specialty templates.
- Low-cost alternatives: Template-based dictation, macros, and “smart phrases” plus post-visit summary generators that don’t record encounters.
Step-by-step implementation (beginner-friendly)
- Define scope: Start with low-risk visit types (e.g., routine follow-up, preventive care).
- Consent workflow: Display a one-sentence script and on-screen consent prompt; allow opt-out with a no-penalty path.
- Template mapping: Map the generated content to fields (HPI, ROS, exam, assessment & plan).
- Error taxonomy: Classify errors (minor phrasing vs. clinical inaccuracy) and set a required review time budget (e.g., 60–120 seconds).
- Pilot with champions: Gather time-motion data: minutes spent documenting during the visit and after hours.
- Quality gates: Require clinician attestation and block note sign-off if high-risk content is unresolved (e.g., mis-stated medication or allergy).
- Iterate prompts and specialty templates: Tune to reduce hallucinations and improve structured data capture.
- Roll out gradually: Expand by clinic and specialty, keeping weekly office hours for troubleshooting.
Beginner modifications and progressions
- Simplify: Limit to SOAP text only before enabling order suggestion or billing codes.
- Progress: Enable visit summaries and patient instructions once note accuracy exceeds a preset threshold and audit logs show stable performance.
Recommended frequency, duration, and metrics
- QA frequency: Weekly sampling of 25–50 notes per site for the first month; monthly thereafter.
- KPIs: Documentation minutes per visit, after-hours time, clinician satisfaction, first-pass acceptance rate, clinically significant error rate, patient satisfaction with explanation and privacy.
- Target cadence: Aim for 20–30% reduction in documentation time within 60 days.
Safety, caveats, and mistakes to avoid
- Consent gaps: Never assume implied consent—make it explicit and quick.
- Overediting by AI: Lock critical fields (meds, allergies) behind explicit clinician review.
- Copy-forward creep: Require date/time stamps for generated text and discourage boilerplate that obscures clinical thinking.
- Privacy and retention: Minimize audio retention; encrypt at rest and in transit; set role-based access.
Mini-plan (sample)
- Step 1: Select two clinics; limit to routine visits; train staff on consent and review.
- Step 2: Track time-savings and error rates weekly; refine prompts/templates.
- Step 3: Expand to one specialty with customized templates; publish a quarterly governance report.
3) Predictive Analytics for Early Deterioration (e.g., Sepsis)
What it is and why it matters
Bedside predictive models use vitals, labs, and clinical notes to alert teams to potential deterioration before conventional scores would. In sepsis, for example, implementations have reported faster antibiotic administration after alerts; however, improvements in hard outcomes are mixed across studies. The signal is promising, but success depends on calibration, clinician trust, and a clean handoff from alert to action.
Core benefits
- Earlier recognition of sepsis, shock, bleeding, respiratory failure, or readmission risk.
- Better resource allocation (rapid response teams focusing on true positives).
- Standardization across shifts and sites.
Requirements and prerequisites
- Data: Near-real-time feeds from EHR and monitors; standardized units; robust missing-data handling.
- Infrastructure: Streaming pipelines, monitoring dashboards, and model version control.
- People: Data engineers, clinical informaticists, nursing leaders, hospitalists/ICU champions.
- Governance: Criteria for model updates, alert thresholds, and sunset plans for underperforming models.
- Low-cost alternatives: Start with validated early warning scores and a nurse-driven escalation protocol while you evaluate machine-learning add-ons.
Step-by-step implementation (beginner-friendly)
- Choose one outcome (e.g., septic shock within 6–12 hours) and lock a precise definition.
- Measure baseline: Time-to-antibiotics, ICU transfer rate, code blue events, mortality on target wards.
- Select candidates: Compare simple scores to machine-learning models on retrospective data; focus on calibration and decision-relevant thresholds, not just AUROC.
- Design the alert: Who receives it, in what channel, with what recommended next steps? Avoid “naked scores”—attach an actionable checklist.
- Silent trial: Run the model without alerts for 2–4 weeks to estimate precision/recall in your environment.
- Progressive go-live: Enable on one ward with a local champion; review every false positive and false negative in daily huddles.
- Tune thresholds: Adjust to achieve a tolerable false-alarm rate per patient-day.
- Monitor drift: Re-evaluate calibration monthly; retrain only with a controlled process and changelog.
Beginner modifications and progressions
- Simplify: Instead of interruptive pop-ups, start with risk dashboards that teams check during rounds.
- Progress: Add task routing (e.g., lactate draw order sets) when precision stabilizes.
Recommended frequency, duration, and metrics
- QA frequency: Weekly during the first 8 weeks; monthly thereafter; ad-hoc after any model change.
- KPIs: Time-to-antibiotics, alert-to-action time, precision at chosen threshold, alerts per 100 patient-days, ICU transfers avoided, mortality (if powered).
- Target cadence: Reduce time-to-antibiotics by an hour or more within 90 days, with acceptable alert burden.
Safety, caveats, and mistakes to avoid
- Alert fatigue: Cap alerts per shift; prioritize by severity.
- Hidden bias: Stratify performance by age, sex, race/ethnicity, and comorbidity; adjust or set alternative thresholds as needed.
- Overreliance: Make clear in training that scores complement—not replace—clinical judgment.
- Definition creep: Freeze your endpoint definition; moving goalposts break monitoring.
Mini-plan (sample)
- Step 1: Run a 2-week silent trial on two wards; pick thresholds that yield <2 alerts per 10 patient-days.
- Step 2: Go live on one ward with an action checklist; review every false positive/negative daily.
- Step 3: After one month, expand to a second ward; publish a one-page outcomes report.
4) AI-Accelerated Drug Discovery and Clinical Trials
What it is and why it matters
AI accelerates discovery by predicting protein and complex structures, proposing novel compounds, prioritizing targets, and optimizing trial design. Structure prediction advances now extend beyond proteins to more complex biomolecular interactions, enabling in-silico screening at a speed and scale that would be impractical otherwise. On the clinical side, AI can mine eligibility criteria, match patients to trials, and even create robust external controls in certain contexts.
Core benefits
- Shorter hypothesis-to-lead timelines and lower screening costs.
- Improved hit rates through better target and scaffold selection.
- Smarter trial design with adaptive cohorts and higher enrollment efficiency.
- Potential repurposing of shelved compounds using mechanistic insights.
Requirements and prerequisites
- Data & compute: Curated assay data; structural databases; GPUs or access to secure cloud computing; a cheminformatics stack.
- People: Computational chemists, structural biologists, translational scientists, and biostatisticians.
- Partnerships: Wet-lab capacity (internal or CRO), IP counsel, and data-sharing agreements.
- Low-cost alternatives: Use pre-trained structure and property predictors with small fine-tunes; partner with academic cores for cryo-EM/X-ray as needed; start with repurposing rather than de-novo design.
Step-by-step implementation (beginner-friendly)
- Pick one disease area with unmet need and accessible models.
- Assemble a knowledge graph linking targets, pathways, phenotypes, and known compounds.
- Prototype an in-silico pipeline: target prioritization → generative proposal → docking/property filtering → retrosynthesis analysis.
- Triage top candidates with orthogonal predictors (toxicity, off-target risk) before any wet-lab spend.
- Design a minimal wet-lab validation (e.g., high-content imaging, biochemical assays) with pre-registered criteria.
- Iterate fast: feed lab results back to retrain property predictors and refine generative constraints.
- Plan clinical translation: AI-assisted trial eligibility mining; synthetic control feasibility; adaptive randomization where appropriate.
Beginner modifications and progressions
- Simplify: Begin with drug repurposing using literature-based embeddings and safety-known molecules.
- Progress: Move to de-novo generative design once your validation loop proves reliable.
Recommended frequency, duration, and metrics
- QA frequency: Gate reviews at each pipeline stage; monthly method audits.
- KPIs: Hit rate vs. baseline library screens, cycle time from concept to lead, predictive accuracy of property models, cost per qualified hit.
- Target cadence: Aim to cut early discovery cycles from months to weeks on your first project.
Safety, caveats, and mistakes to avoid
- Data leakage and overfitting: Keep hold-out sets truly external; document provenance.
- Reproducibility gaps: Version datasets, code, and models; preregister experiment plans.
- Wet-lab alignment: Avoid sending unrealistic molecules to the lab—screen for synthesis feasibility early.
- Regulatory readiness: Maintain traceability and a documented model lifecycle to support future submissions.
Mini-plan (sample)
- Step 1: Run a repurposing pilot in one indication; test the top five mechanistically plausible candidates in vitro.
- Step 2: If signal is positive, launch a de-novo design sprint with explicit ADMET constraints.
- Step 3: Prepare a translational plan for trial matching and synthetic controls.
5) Patient-Facing AI and Remote Care (Triage, Wearables, Digital Therapeutics)
What it is and why it matters
Patient-facing AI includes symptom checkers, triage chatbots, and virtual navigators, along with wearable-driven programs that detect arrhythmias, track blood pressure trends, or monitor chronic conditions at home. In controlled studies and reviews, large language models can triage cases with accuracy comparable to trained staff on curated vignettes, while wearables show high sensitivity and specificity for detecting atrial fibrillation. Mental health chatbots, when used as adjuncts, can reduce symptoms in short-course programs. The promise is real—but these tools require careful guardrails, escalation rules, and clear messaging that they do not replace clinicians.
Core benefits
- 24/7 access and reduced wait times for routine questions.
- Early detection of silent conditions (e.g., arrhythmias).
- Better adherence to care plans via nudges and personalized education.
- Lower avoidable emergency visits through timely triage and escalation.
Requirements and prerequisites
- Technology: Patient portal or app; device inventory (BP cuffs, watches, patches); secure messaging and telehealth integration.
- Protocols: Red-flag keywords and escalation paths; coverage hours; response SLAs.
- People: Nurse navigators and on-call clinicians; privacy compliance staff.
- Low-cost alternatives: SMS-based chat flows and phone-tree automation with clear hand-offs to humans; bring-your-own-device models for step counting or basic heart-rate monitoring.
Step-by-step implementation (beginner-friendly)
- Start with one cohort (e.g., post-AF ablation patients or high-risk hypertension) and define success metrics (detection PPV, time-to-response, patient-reported outcomes).
- Choose devices and chatbot scope: education and navigation first; avoid diagnostic claims.
- Create a triage protocol: red-flag keywords (e.g., chest pain, syncope, suicidal ideation) trigger immediate human review or emergency guidance.
- Pilot for 4–8 weeks: measure escalation rates, false alarms, patient satisfaction, and adherence.
- Refine onboarding and messaging: make it clear the bot is not a clinician; provide easy escalation channels.
- Integrate with care pathways: ensure flagged events create tasks, not just messages.
Beginner modifications and progressions
- Simplify: Deploy FAQ-only assistants for administrative topics (refills, appointment reminders) before symptom triage.
- Progress: Add structured symptom flows and device-driven alerts once human coverage and escalation rules prove reliable.
Recommended frequency, duration, and metrics
- QA frequency: Weekly transcript reviews for the first month; monthly thereafter; incident reviews for every red-flag case.
- KPIs: Response time, escalation rate, detection precision, patient satisfaction, portal adoption, avoidable ER visits per 1,000 members.
- Target cadence: Achieve <5 minutes median response time during staffed hours; <10% escalation for administrative queries; stable PPV for device alerts.
Safety, caveats, and mistakes to avoid
- Overreach: Don’t allow bots to give diagnostic or treatment directives.
- Privacy: Disclose data uses plainly; offer opt-out; minimize retention.
- Equity: Provide non-smartphone options and translated content.
- Coverage gaps: Bots must never be the only on-call “responder”; define coverage hours and hand-offs.
Mini-plan (sample)
- Step 1: Launch an administrative assistant for refills and scheduling; measure response times and satisfaction.
- Step 2: Layer a hypertension remote monitoring program with thresholds for human escalation.
- Step 3: Add a symptom navigator for low-acuity complaints after a successful 8-week review.
Quick-Start Checklist
- Identify one clinical use case per domain (imaging, docs, prediction, discovery, remote care).
- Stand up a governance group with clinical, IT, privacy, and quality leaders.
- Draft scope, success metrics, and safety thresholds for each pilot.
- Ensure consent, logging, and audit are in place before go-live.
- Run silent or shadow pilots to establish local performance.
- Start small, measure weekly, and publish a one-page outcomes brief each month.
Troubleshooting & Common Pitfalls
- “The model looked great on paper but failed locally.”
Likely data shift or workflow mismatch. Re-check calibration on your scanner mix or patient population; review where in the workflow clinicians see and action the output. - “Too many alerts; staff are ignoring them.”
Tune thresholds to cap alerts per patient-day. Use tiered alerting (info → warning → critical) and attach checklists so each alert prompts an action, not just a number. - “Notes still take forever to review.”
Narrow scope to SOAP only, turn off order suggestions, and enforce a two-minute review budget. Track error taxonomy and fix the top two causes. - “Patients think the chatbot is their doctor.”
Make the role explicit at onboarding, add a two-line disclaimer in every conversation, and place a prominent “Talk to a human” button. - “Leaders ask for ROI before we start.”
Define intermediate value: minutes saved per visit, turnaround time, antibiotic timing, and detection improvements. Cost follows when time savings and outcomes stabilize. - “Equity concerns.”
Stratify metrics and sample transcripts by demographic groups; translate materials; offer phone-based alternatives.
How to Measure Progress (and Prove It)
Imaging and diagnostics
- Detection rate, recall rate, time-to-report, second-read variance.
- Drift metrics by device vendor and site.
- Monthly peer review of discordant cases.
Generative documentation
- Minutes of documentation during and after visits; first-pass acceptance; clinically significant error rate.
- Clinician Net Promoter Score; patient satisfaction with communication and privacy.
Predictive analytics
- Alert precision/recall; alerts per 100 patient-days; time-to-antibiotics; ICU transfers.
- Calibration slope and intercept; subgroup performance.
Drug discovery & trials
- Hit rate vs. baseline; time from hypothesis to validated lead; ADMET prediction accuracy; trial enrollment velocity.
Patient-facing AI
- Response time, escalation rate, device alert PPV, avoidable ER visits, adherence to remote monitoring.
- Red-flag incident reviews with corrective actions.
A Simple 4-Week Starter Plan
Week 1 — Decide & baseline
- Pick one use case in two domains (e.g., imaging + documentation).
- Establish baseline metrics and collect a small reference dataset.
- Form your governance group; write a one-page safety plan.
Week 2 —Silent pilots & guardrails
- Run silent pilots for imaging triage and documentation drafts.
- Finalize consent language; configure logging and audit dashboards.
- Create an error taxonomy and a weekly review cadence.
Week 3 —Go-live (limited) & feedback loop
- Enable imaging reader-assist at one site; enable ambient drafting for routine visits in one clinic.
- Hold end-of-week safety huddles; tune thresholds and prompts.
Week 4 —Measure & share
- Publish a one-page outcomes brief: time saved, turnaround, error rates.
- Decide on expansion, pause, or course-correction based on data.
- Line up the next two domains (predictive alerts, patient-facing assistant) using the same playbook.
FAQs
- Will AI replace clinicians?
No. The highest-value use cases augment clinicians—surfacing patterns, drafting notes, or prioritizing work—while final judgment, empathy, and accountability remain human. - How do we keep AI from “making things up”?
Limit scope; require explicit review of critical fields; use error taxonomies and sampling audits; track first-pass acceptance and clinically significant error rates. - Do we need special hardware?
For most deployments, secure cloud inference or modest on-prem GPUs suffice. Imaging workloads benefit from stronger GPUs; documentation tools primarily need reliable microphones and network. - What about regulation?
Expect evolving lifecycle guidance for AI-enabled software. Maintain version control, changelogs, validation reports, and a process for updating models with post-market monitoring. - Is it worth it for small clinics?
Yes—start with ambient drafting for routine visits and administrative chat assistants. Many tools offer per-user pricing and require minimal IT support. - How do we address bias and fairness?
Measure performance across subgroups; adjust thresholds or workflows as needed; include diverse data in validation; solicit patient feedback from underrepresented groups. - Can we use AI for mental health?
As an adjunct, yes—education, mood tracking, and coping skills can help. For diagnosis or crisis, escalate to licensed professionals and emergency pathways. - What’s the fastest path to ROI?
Documentation relief typically shows rapid time savings. Imaging triage can reduce backlogs and overtime. Predictive analytics take longer but can yield powerful operational improvements if alert burden stays manageable. - How do we prevent alert fatigue?
Tune thresholds, prioritize alerts, attach checklists, and cap alert rates per patient-day. Regularly prune or pause underperforming rules. - What happens when the model drifts?
You’ll see calibration degrade or false alarms rise. Investigate data pipeline changes, scanner upgrades, or population shifts; recalibrate or retrain under a controlled, documented process. - Can patients opt out of AI?
Yes—and they should be able to. Offer clear opt-out paths for ambient recording, chatbot interactions, and remote monitoring without penalizing patients. - How do we scale from pilots to enterprise?
Standardize procurement, validation, and monitoring. Publish monthly safety and performance dashboards. Build reusable integration patterns and training.
Conclusion
AI in healthcare is moving past proof-of-concept into the fabric of daily care—when it’s implemented with humility, guardrails, and relentless measurement. Start small, choose use cases with clear value, involve your clinicians early, and show your work with simple, credible metrics. The impact compounds as you scale.
CTA: Pick one high-yield use case this month, set a baseline, and run a 4-week pilot with real metrics—then let the data decide your next step.
References
- IDx-DR – DEN180001 De Novo Summary, U.S. Food & Drug Administration, 2018. https://www.accessdata.fda.gov/cdrh_docs/reviews/DEN180001.pdf
- Pivotal trial of an autonomous AI-based diagnostic system for detection of diabetic retinopathy in primary care offices, npj Digital Medicine, 2018. https://www.nature.com/articles/s41746-018-0040-6
- Nationwide real-world implementation of AI for cancer screening, Nature Medicine, 2025. https://www.nature.com/articles/s41591-024-03408-6
- Artificial intelligence for breast cancer screening in a real-world, single-read setting, Nature Communications, 2025. https://www.nature.com/articles/s41467-025-57469-3
- Artificial intelligence for breast cancer screening in clinical practice: replacing one reader with AI, The Lancet Digital Health, 2023. https://www.thelancet.com/journals/landig/article/PIIS2589-7500%2823%2900153-X/fulltext
- Ambient Artificial Intelligence Scribes: Learnings after 1 Year, NEJM Catalyst, 2025. https://catalyst.nejm.org/doi/full/10.1056/CAT.25.0040
- AI scribes save 15,000 hours—and restore the human side of medicine, American Medical Association, 2025. https://www.ama-assn.org/practice-management/digital-health/ai-scribes-save-15000-hours-and-restore-human-side-medicine
- Why AI may be listening in on your next doctor’s appointment, The Wall Street Journal, 2025. https://www.wsj.com/health/healthcare/ai-ambient-listening-doctor-appointment-e7afd587
- This technology is becoming beloved by doctors and patients alike, The Washington Post, 2025. https://www.washingtonpost.com/opinions/2025/03/25/ambient-ai-health-care-artificial-intelligence/
- FDA-Authorized AI/ML Tool for Sepsis Prediction, NEJM AI, 2024. https://ai.nejm.org/doi/full/10.1056/AIoa2400867
- Early Warning Scores With and Without Artificial Intelligence: A Cohort Study, JAMA Network Open, 2024. https://jamanetwork.com/journals/jamanetworkopen/fullarticle/2824885
- Review of AlphaFold 3: Transformative Advances in Drug Discovery, Frontiers in Molecular Biosciences (PMC), 2024. https://pmc.ncbi.nlm.nih.gov/articles/PMC11292590/
- The Role of AI in Drug Discovery: Challenges, Advances, and Opportunities, International Journal of Molecular Sciences (PMC), 2023. https://pmc.ncbi.nlm.nih.gov/articles/PMC10302890/
- The future of pharmaceuticals: Artificial intelligence in drug discovery and development, Engineering (Elsevier), 2025. https://www.sciencedirect.com/science/article/pii/S2095177925000656
- Artificial intelligence revolution in drug discovery, International Journal of Pharmaceutics (Elsevier), 2025. https://www.sciencedirect.com/science/article/pii/S037851732500626X
- Diagnostic Accuracy of ChatGPT for Patients’ Triage in Emergency Departments, Healthcare Informatics Research (PMC), 2024. https://pmc.ncbi.nlm.nih.gov/articles/PMC11407534/
- Emergency department triaging using ChatGPT based on the Emergency Severity Index, Scientific Reports, 2024. https://www.nature.com/articles/s41598-024-73229-7
- Triage Performance Across Large Language Models and ChatGPT vs. ED Staff, Journal of Medical Internet Research, 2024. https://www.jmir.org/2024/1/e53297/